
- Updated: June 24, 2026
- 6 min read
Process-Reward Tactic Evolution for Long-Horizon Bioinformatics Workflows
Direct Answer
Process‑Reward Tactic Evolution (PRTE) is a training framework that teaches large‑language‑model (LLM) agents to build, execute, and validate complex bioinformatics pipelines on the Galaxy platform. By converting verified workflow rollouts into reusable “tactics,” PRTE enables agents to complete long‑horizon tasks with higher biological correctness and lower execution overhead.
Background: Why This Problem Is Hard
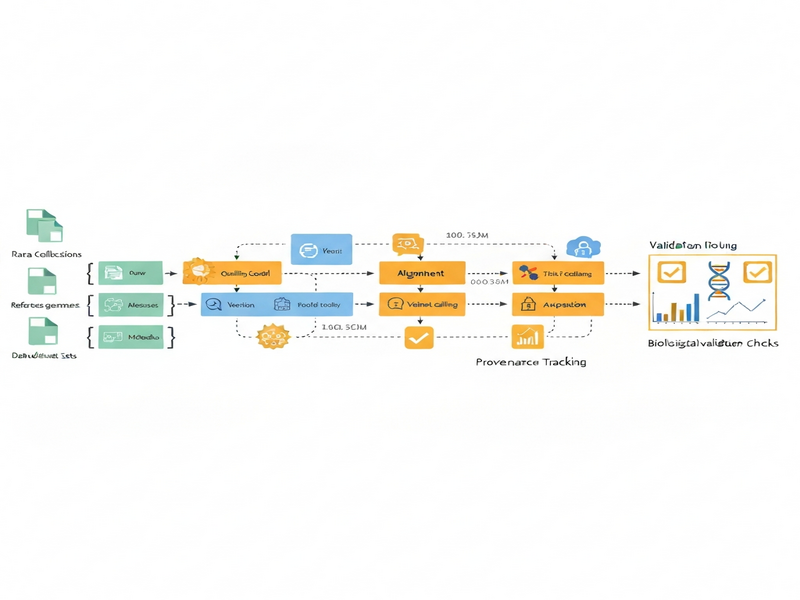
Bioinformatics analyses often span dozens of tools, each with strict input‑type requirements, provenance tracking, and domain‑specific quality checks. Researchers typically orchestrate these steps through workflow managers such as Galaxy, which represent pipelines as directed acyclic graphs (DAGs). Automating this process with AI agents faces three intertwined challenges:
- Tool heterogeneity: Every tool expects a particular file format, metadata schema, or collection type, making naïve code generation error‑prone.
- Long‑horizon reasoning: A single analysis can require 10–30 sequential actions—data discovery, workflow construction, execution monitoring, debugging, and result validation—far beyond the few‑step horizon most LLM agents handle today.
- Biological verification: Even if a pipeline runs without technical errors, the scientific output must satisfy domain‑specific checks (e.g., alignment quality, variant calling confidence), which are rarely encoded in generic tool wrappers.
Current approaches either rely on static prompt engineering, which cannot adapt to runtime failures, or on reinforcement‑learning‑style agents that lack a memory of successful patterns. Consequently, AI‑driven bioinformatics automation remains brittle, limiting its adoption in production labs.
What the Researchers Propose
The authors introduce Process‑Reward Tactic Evolution (PRTE), a Galaxy‑centric training loop that transforms successful workflow executions into a library of reusable tactics. PRTE consists of three core components:
- Agent Gym: A curriculum of Galaxy tasks ranging from simple data imports to multi‑tool analyses, providing a sandbox for agents to practice.
- Process Verifiers: Automated judges that score each step on four dimensions—workflow construction fidelity, software interaction correctness, execution success, and biological output validity.
- Tactic Library: A distilled collection of high‑level action sequences (tactics) that encode “how to” knowledge, such as “bind a FASTQ collection to a trimming tool” or “recover from a failed job by adjusting memory limits.”
During training, agents explore the task space, receive reward signals from the verifiers, and store both successful and failed traces. The evolution process continuously refines the tactic library, enabling the agent to recall and adapt proven strategies when faced with new, unseen pipelines.
How It Works in Practice
At inference time, PRTE follows a deterministic pipeline:
- Task Ingestion: The agent receives a high‑level scientific goal (e.g., “perform RNA‑seq differential expression”).
- Data Exploration: Using Galaxy’s API, the agent queries available datasets, identifies required input types, and assembles collections.
- Workflow Synthesis: The agent consults the tactic library to select a base DAG template, then customizes node parameters based on the current data landscape.
- Execution & Monitoring: The constructed workflow is submitted to Galaxy. Process verifiers watch job logs, detect stalls or failures, and trigger corrective tactics (e.g., “increase RAM,” “re‑run with different seed”).
- Biological Validation: After successful execution, domain‑specific validators (e.g., FastQC for quality, DESeq2 for statistical significance) assess the results. If validation fails, the agent iterates using fallback tactics.
- Result Delivery: The final, validated outputs are packaged and returned to the user, along with a provenance report generated from Galaxy’s history tracking.
What sets PRTE apart is the explicit separation between process supervision (verifiers) and knowledge accumulation (tactics). Rather than learning from raw reward signals alone, the agent builds a structured memory of “what worked” and “why it worked,” dramatically reducing trial‑and‑error cycles.
Evaluation & Results
The authors benchmarked PRTE against two baselines:
- No‑Memory Agent: An LLM that generates workflow code from scratch for each task, without any tactic reuse.
- Reflection‑Style Agent: An LLM that can introspect on its previous attempts but does not maintain a curated tactic library.
Evaluation used two curated suites:
- BioWorkflow Bench: A collection of 50 peer‑reviewed Galaxy pipelines spanning genomics, transcriptomics, and metagenomics.
- BioAgent Bench: A set of 30 novel tasks derived from recent publications, deliberately designed to test generalization.
Key findings include:
- Completion Rate: PRTE completed 87% of BioWorkflow Bench pipelines versus 54% (No‑Memory) and 68% (Reflection).
- Biological Correctness: 81% of PRTE’s outputs passed domain‑specific validators, compared with 46% and 62% for the baselines.
- Execution Efficiency: Average wall‑clock time per pipeline dropped by 32% thanks to early failure detection and tactic‑driven recovery.
- Memory Utilization: The tactic library grew to 212 distinct tactics after 10,000 training rollouts, yet remained compact enough to be queried in sub‑second latency.
These results demonstrate that process‑supervised tactic accumulation not only improves raw success rates but also yields scientifically trustworthy outcomes—an essential requirement for production bioinformatics.
Why This Matters for AI Systems and Agents
PRTE’s architecture offers a blueprint for building robust, long‑horizon AI agents in any domain where toolchains are complex and correctness is non‑negotiable. For practitioners, the framework highlights three actionable takeaways:
- Process‑Level Supervision: Embedding domain‑specific verifiers turns opaque execution into a feedback‑rich loop, enabling agents to self‑correct without human intervention.
- Reusable Tactics: Curating high‑level action patterns creates a knowledge base that can be shared across projects, reducing the need for retraining from scratch.
- Curriculum‑Driven Training: Organizing tasks from simple to complex mirrors human learning and accelerates skill acquisition for LLM agents.
Enterprises looking to automate scientific pipelines can map PRTE’s components onto existing orchestration platforms. For example, the Workflow automation studio already supports drag‑and‑drop DAG construction and could integrate a tactic library to provide AI‑assisted suggestions. Similarly, the UBOS platform overview outlines a modular architecture where process verifiers could be plugged in as micro‑services, turning any AI agent into a self‑healing workflow executor.
What Comes Next
While PRTE marks a significant step forward, several open challenges remain:
- Cross‑Platform Generalization: Extending tactics beyond Galaxy to other workflow engines (e.g., Nextflow, Snakemake) will require abstracting tool semantics.
- Dynamic Knowledge Update: As new bioinformatics tools emerge, the tactic library must evolve without catastrophic forgetting.
- Human‑in‑the‑Loop Validation: Integrating expert review into the verification loop could further boost confidence for clinical applications.
- Scalable Verification: Process verifiers currently rely on deterministic checks; scaling to stochastic simulations or large‑scale omics datasets will demand more efficient validation heuristics.
Future research may explore meta‑learning approaches that let agents infer new tactics on the fly, or hybrid systems that combine symbolic reasoning with LLM‑driven generation. From an industry perspective, building a marketplace of vetted tactics—similar to software libraries—could accelerate adoption across biotech startups and large research institutions.
For teams ready to experiment, the UBOS partner program offers early access to API endpoints and sandbox environments where custom verifiers and tactic libraries can be prototyped.
Illustration Placeholder
References
Process‑Reward Tactic Evolution for Long‑Horizon Bioinformatics Workflows (arXiv)