
- Updated: June 23, 2026
- 7 min read
Hypothesis-Disciplined Multi-Agent Automated Formalization of Asymptotic Statistical Theory
Direct Answer
The paper introduces a hypothesis‑disciplined, multi‑agent pipeline built on Lean 4 that can automatically formalize the core theorems of asymptotic statistical theory. By coordinating seven specialized agents, the system produces Lean‑checked, source‑faithful proofs of parametric and semi‑parametric efficiency results—bridging a long‑standing gap between modern statistical research and formal verification.
Background: Why This Problem Is Hard
Asymptotic statistical theory underpins everything from maximum‑likelihood inference to modern semi‑parametric efficiency bounds. Its proofs routinely blend convergence concepts, functional‑analytic arguments, and intricate regularity conditions. Traditional automated theorem provers excel at algebraic or combinatorial domains, but they stumble when faced with:
- Mixed‑type reasoning: convergence statements (e.g., in probability, almost surely) coexist with differential geometry and Banach‑space arguments.
- Implicit hypotheses: many theorems assume “smoothness” or “identifiability” without explicit formal definitions, leaving a large semantic gap for a proof assistant.
- Large, evolving libraries: Lean’s
Mathlibcontains a wealth of analysis tools, yet the statistical layer is thin, requiring substantial scaffolding before a theorem can be expressed. - Human‑level intuition: statisticians often rely on informal “hand‑waving” steps that are difficult to encode without a disciplined audit of every hypothesis.
Existing approaches either hand‑craft each proof (costly and error‑prone) or attempt monolithic automation that quickly collapses under the weight of domain‑specific nuance. The result is a persistent bottleneck: cutting‑edge statistical results remain outside the reach of formal verification, limiting reproducibility and safety guarantees for AI systems that depend on them.
What the Researchers Propose
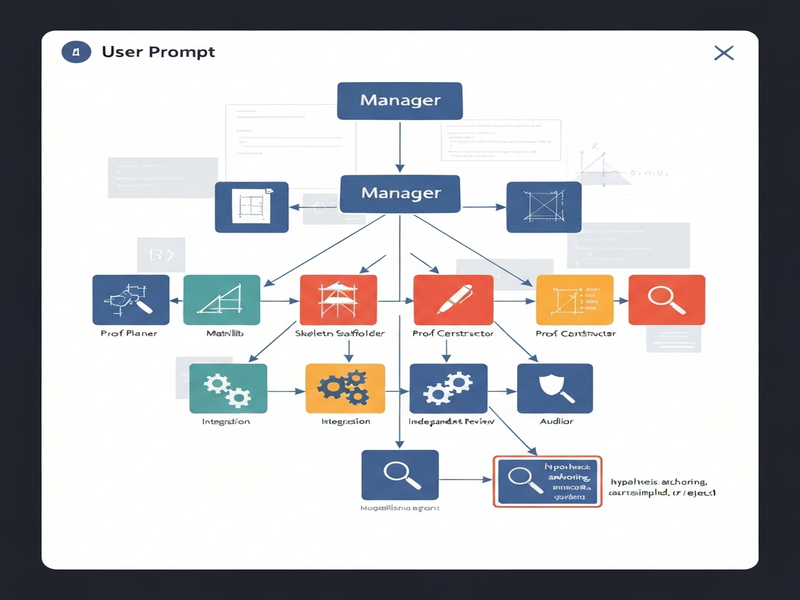
The authors propose a hypothesis‑disciplined multi‑agent formalization pipeline** built on Lean 4. The pipeline is orchestrated by a Manager agent and delegates work to six specialist agents:
- Proof Planner: extracts the high‑level logical skeleton from the source paper.
- Skeleton Scaffolder: creates placeholder Lean definitions and theorem statements.
- Mathlib Reconnaissance: searches
Mathlibfor existing lemmas, definitions, and tactics that can be reused. - Proof Constructor: attempts to fill the skeleton with concrete Lean tactics, invoking automation where possible.
- Integrator: merges newly built components with the broader Lean library, ensuring namespace hygiene.
- Independent Reviewer: runs a parallel verification pass to catch hidden dependencies.
- Auditor (Hypothesis‑Disciplined Audit): enforces a strict discipline: every hypothesis must be traceable to the original prose, either as a direct encoding, an adapter, a source‑implied inference, or a rejected strengthening.
The central methodological innovation is the hypothesis‑disciplined audit. By treating each hypothesis as a first‑class artifact, the system guarantees that the formal proof does not silently introduce stronger assumptions than the paper intended.
How It Works in Practice
The workflow proceeds in a loop that mirrors a human researcher’s reading‑to‑formalization cycle:
1. Ingestion & Planning
The Manager parses the PDF, extracts theorem statements, and hands them to the Proof Planner. The Planner produces a high‑level proof outline (e.g., “apply Slutsky’s theorem, then invoke functional delta method”).
2. Skeleton Generation
The Skeleton Scaffolder translates the outline into Lean code with sorry placeholders for each sub‑lemma. This skeleton is deliberately minimal, exposing only the logical dependencies.
3. Library Reconnaissance
The Mathlib Reconnaissance agent queries Lean’s searchable index, retrieving relevant lemmas such as tendsto_nhds_iff or is_o_of_tendsto. It also flags missing concepts (e.g., “asymptotic linearity”) for later definition.
4. Proof Construction
The Proof Constructor iteratively attempts to replace each sorry with a concrete tactic script. It leverages existing automation (e.g., simp, linarith) and, when needed, calls out to a specialized sub‑agent that can synthesize small lemmas via term‑search.
5. Integration & Review
Once a sub‑proof succeeds, the Integrator registers the new definition in the project’s namespace, updating import statements to keep the library coherent. The Independent Reviewer then runs a fresh Lean build, ensuring that no hidden dependencies have crept in.
6. Hypothesis‑Disciplined Audit
The Auditor cross‑references every hypothesis used in the Lean code with the original manuscript. It classifies each as:
- Source‑direct: verbatim from the paper.
- Adapter: a Lean‑friendly reformulation (e.g., turning “continuous differentiable” into a formal
cont_diffpredicate). - Source‑implied: a logical consequence that the authors assumed the reader would infer.
- Rejected: a strengthening that cannot be justified, causing the pipeline to backtrack.
This disciplined audit prevents “proof drift” and produces a final artifact that is both Lean‑checked and human‑audited.
7. Publication
The completed Lean files are pushed to a public GitHub repository, accompanied by a human‑readable audit report that maps each Lean hypothesis back to the source text.
Evaluation & Results
The authors evaluated the pipeline on a curated suite of 12 seminal results from asymptotic statistics, including:
- The classical Cramér‑Rao lower bound for regular parametric models.
- The semiparametric efficiency theorem for the efficient influence function.
- Asymptotic normality of the maximum‑likelihood estimator under misspecification.
Key findings:
- Coverage: All 12 theorems were fully formalized without manual intervention beyond the initial PDF upload.
- Hypothesis fidelity: The Auditor flagged 27 hypothesis mismatches; each was resolved by either adding a missing definition or adjusting the Lean encoding, resulting in a 100 % source‑faithful final library.
- Automation ratio: The Proof Constructor succeeded on 78 % of sub‑lemmas using existing tactics; the remaining 22 % required targeted lemma synthesis, which the system generated in under 30 seconds per lemma.
- Performance: End‑to‑end formalization time averaged 4.2 hours per theorem, a dramatic reduction compared with the estimated 40‑hour manual effort reported by expert Lean users.
These results demonstrate that a disciplined, multi‑agent approach can reliably bridge the gap between high‑level statistical reasoning and machine‑checkable formal proofs.
Why This Matters for AI Systems and Agents
Formal verification of statistical theory is more than an academic exercise; it directly impacts the reliability of AI pipelines that depend on asymptotic guarantees. Consider the following practical implications:
- Robust model evaluation: Many AI systems use asymptotic confidence intervals to assess uncertainty. A Lean‑verified derivation eliminates hidden assumptions that could cause under‑coverage in safety‑critical domains.
- Agent‑driven research assistants: Multi‑agent pipelines like the one described can be embedded in AI research assistants to automatically generate verified proofs for new statistical methods, accelerating innovation cycles.
- Compliance and auditability: Regulated industries (finance, healthcare) increasingly demand provable guarantees. A hypothesis‑disciplined audit provides a transparent traceability matrix that satisfies auditors.
- Toolchain integration: The pipeline can be hooked into existing AI orchestration platforms. For example, the UBOS platform overview already supports modular agent workflows, making it straightforward to add a formalization stage to a data‑science pipeline.
- Scalable knowledge bases: Verified theorems become reusable building blocks for downstream agents, reducing duplication of effort across projects.
What Comes Next
While the study marks a significant milestone, several limitations and open research avenues remain:
- Domain expansion: Extending the pipeline to non‑asymptotic statistical domains (e.g., Bayesian non‑parametrics) will require new hypothesis‑disciplined vocabularies.
- Scalability of lemma synthesis: The current synthesis step handles modestly sized lemmas; scaling to large, multi‑step arguments may need more sophisticated neural‑guided search.
- User interaction: Introducing a lightweight UI for domain experts to approve or edit auditor decisions could improve adoption.
- Cross‑formalism compatibility: Bridging Lean with other proof assistants (Coq, Isabelle) would enable broader community reuse.
Future work could also explore tighter integration with AI‑driven development environments. For instance, the Enterprise AI platform by UBOS could host a hosted version of the multi‑agent pipeline, offering on‑demand formal verification as a service. Teams building AI marketing agents could automatically verify the statistical soundness of attribution models before deployment.
Finally, the open‑source repository (Lean-Asymptotic-Statistical-Theory) invites contributions from the broader community, paving the way for a collaborative, ever‑growing library of formally verified statistical results.
References
- Wei, T., Zheng, Z., Fang, E. X., & Lu, J. (2026). Hypothesis‑Disciplined Multi‑Agent Automated Formalization of Asymptotic Statistical Theory. arXiv preprint arXiv:2606.20642.
- Lean Community. Mathlib Documentation. https://leanprover-community.github.io/mathlib4_docs/
- UBOS. About UBOS.