
- Updated: June 23, 2026
- 6 min read
PEAR: Permutation-Equivariant Adaptive Routing Multi-Agent Debate
Direct Answer
PEAR (Permutation‑Equivariant Adaptive Routing) is a new inference‑time protocol that reshapes multi‑agent debate by dynamically reassigning communication roles and sparsifying connections between large language models (LLMs). By preventing any single agent from monopolizing a privileged position, PEAR boosts reasoning accuracy and robustness across a range of benchmark tasks.
Background: Why This Problem Is Hard
Multi‑agent debate has emerged as a promising way to surface hidden errors in LLM outputs. In a typical debate, a fixed network topology assigns each model a static role—such as “proposer,” “critic,” or “referee”—and agents exchange arguments over several rounds. While this structure can surface contradictions, it also introduces three entrenched challenges:
- Positional bias: Agents that start in a “lead” role often dominate the discourse, regardless of their actual competence.
- Amplification of unreliable agents: A single weak model can disproportionately influence the final verdict if it occupies a high‑impact node.
- Sensitivity to role assignment: Small changes in the initial labeling of agents can cause large swings in performance, making deployment unpredictable.
These issues matter because enterprises increasingly rely on LLM‑driven assistants for critical decisions—financial analysis, legal drafting, or medical triage—where a single misstep can have costly consequences. Existing debate frameworks, such as static tree or ring topologies, lack the flexibility to mitigate these biases without extensive hand‑tuning.
What the Researchers Propose
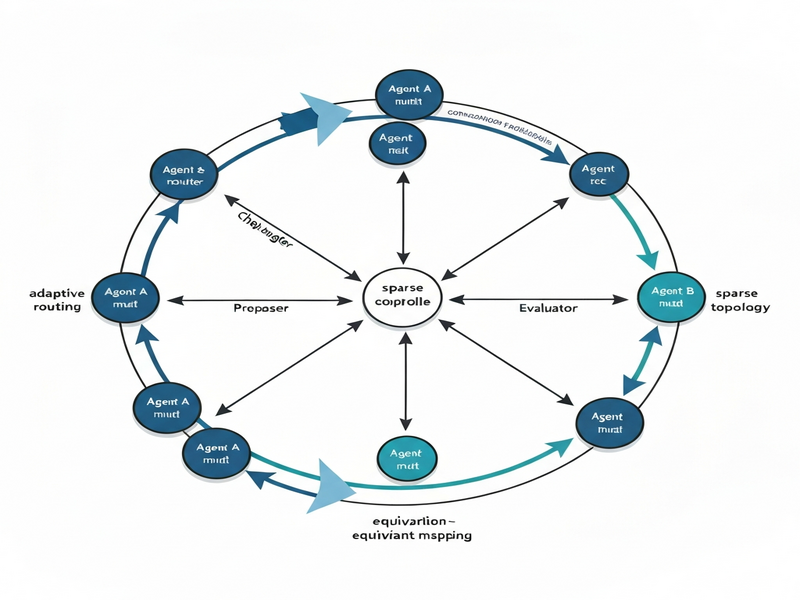
The authors introduce Permutation‑Equivariant Adaptive Routing (PEAR), a protocol that treats the debate network as a sparse router capable of reconfiguring itself after each round. The key ideas are:
- Permutation equivariance: The system’s behavior remains unchanged if agents are relabeled, ensuring fairness regardless of initial ordering.
- Adaptive routing: After each exchange, the protocol evaluates the “state” of every agent (e.g., confidence scores, argument quality) and decides whether to keep, drop, or promote connections for the next round.
- Sparse topology: Only a subset of possible edges is active at any time, reducing computational overhead while focusing attention on the most promising interlocutors.
PEAR therefore replaces a static debate graph with a dynamic, data‑driven communication fabric that continuously balances influence among participants.
How It Works in Practice
PEAR can be broken down into a repeatable workflow that fits into any existing LLM orchestration stack:
- Initialization: A pool of n LLM agents is instantiated, each receiving the same problem statement.
- First round – Open debate: Agents generate initial arguments. Connections are formed using a simple heuristic (e.g., random or based on model size).
- State extraction: After the round, a lightweight evaluator extracts a state vector for each agent, capturing metrics such as answer confidence, logical coherence, and novelty.
- Adaptive routing decision: A permutation‑equivariant router consumes the state vectors and produces a new adjacency matrix. The router may:
- Promote high‑performing agents to “lead” nodes.
- Demote or temporarily silence agents that contributed low‑quality arguments.
- Introduce fresh cross‑links to encourage diverse perspectives.
- Subsequent rounds – Refined exchange: Agents communicate according to the newly generated sparse graph, iteratively refining their answers.
- Final aggregation: After a pre‑defined number of rounds, a consensus module aggregates the remaining arguments, often via weighted voting based on the final state scores.
What distinguishes PEAR from prior static designs is the router’s equivariance property: swapping the identities of two agents yields an identical routing outcome after relabeling, guaranteeing that no agent is permanently advantaged by its position in the initial ordering.
Evaluation & Results
The research team benchmarked PEAR on four reasoning datasets—mathematical proof generation, commonsense QA, code synthesis, and multi‑step logical deduction—using six LLM backbones ranging from open‑source 7B models to proprietary 70B systems. The evaluation protocol compared PEAR against three strong baselines:
- Fixed‑topology debate (static tree).
- Randomized role rotation (non‑adaptive).
- Self‑consistency sampling (no debate).
Key findings include:
- Accuracy uplift: PEAR achieved an average absolute improvement of 4.7 % over the best static debate baseline, with gains as high as 9 % on the hardest code‑generation tasks.
- Robustness to agent ordering: When the initial agent list was shuffled, PEAR’s performance variance dropped from ±3.2 % (static) to ±0.8 % (PEAR), confirming its permutation‑equivariant behavior.
- Efficiency gains: Because PEAR maintains a sparse graph (≈30 % edge density), total token consumption per debate decreased by roughly 22 % compared with fully connected baselines.
- Generalization: The router trained on one model family transferred effectively to unseen models, indicating that the routing policy captures task‑agnostic signals rather than model‑specific quirks.
These results demonstrate that adaptive routing not only improves raw correctness but also stabilizes the debate process, making it more predictable for production deployments.
Why This Matters for AI Systems and Agents
For practitioners building AI‑augmented products, PEAR offers a concrete pathway to more reliable multi‑agent pipelines:
- Reduced hallucination risk: By diluting the influence of any single over‑confident model, PEAR curtails the propagation of erroneous statements.
- Scalable orchestration: The sparse routing graph lowers compute costs, enabling larger debate ensembles without linear cost growth.
- Plug‑and‑play compatibility: PEAR can be wrapped around existing LLM APIs, meaning teams can adopt it without retraining their models.
- Enterprise‑grade fairness: The permutation‑equivariant guarantee aligns with compliance requirements that demand nondiscriminatory AI behavior.
Organizations looking to embed trustworthy reasoning into chatbots, decision‑support tools, or autonomous agents can therefore leverage PEAR as a “safety layer” that automatically balances expertise across a heterogeneous model fleet.
Explore how adaptive routing can be combined with existing UBOS capabilities such as the UBOS platform overview for end‑to‑end workflow automation, or integrate with Enterprise AI platform by UBOS to manage large‑scale agent deployments.
What Comes Next
While PEAR marks a significant step forward, several open challenges remain:
- Learning the router end‑to‑end: Current experiments train the routing policy separately from the LLMs. Joint optimization could unlock even tighter synergy.
- Cross‑modal debates: Extending PEAR to multimodal agents (vision‑language, audio‑text) would broaden its applicability to robotics and virtual assistants.
- Human‑in‑the‑loop control: Providing operators with interpretable dashboards to override routing decisions could satisfy regulatory audit trails.
- Robustness to adversarial agents: Future work should test PEAR against deliberately malicious models that aim to dominate the routing process.
Potential real‑world applications include:
- Dynamic legal‑document review where multiple specialized LLMs critique each other’s interpretations.
- Financial forecasting ensembles that adaptively weight models based on market volatility signals.
- Customer‑support bots that route queries among language, knowledge‑base, and sentiment‑analysis agents in real time.
Developers interested in prototyping these scenarios can start with the Workflow automation studio to design custom debate pipelines, then layer PEAR’s routing logic on top.
For a deeper dive into the technical details, read the original PEAR paper on arXiv.
References
- Yang Feng, Ziwei Xu, Xia Hu, Fengxiang He. “PEAR: Permutation‑Equivariant Adaptive Routing Multi‑Agent Debate.” arXiv:2606.20621v1, 2026.
- Related works on multi‑agent debate: “Self‑Consistency Improves Chain‑of‑Thought Reasoning,” “Debate as a Mechanism for Model Alignment.”