
- Updated: June 22, 2026
- 7 min read
Hybrid Neural World Models – A Deep Dive
Direct Answer
The paper Hybrid Neural World Models (arXiv) introduces a single neural network that can predict physical states at any future time horizon while simultaneously exposing an implicit error map that highlights shocks, fronts, and contacts. This matters because it delivers order‑of‑magnitude speedups over traditional PDE solvers without sacrificing safety‑critical accuracy in regions where dynamics change abruptly.
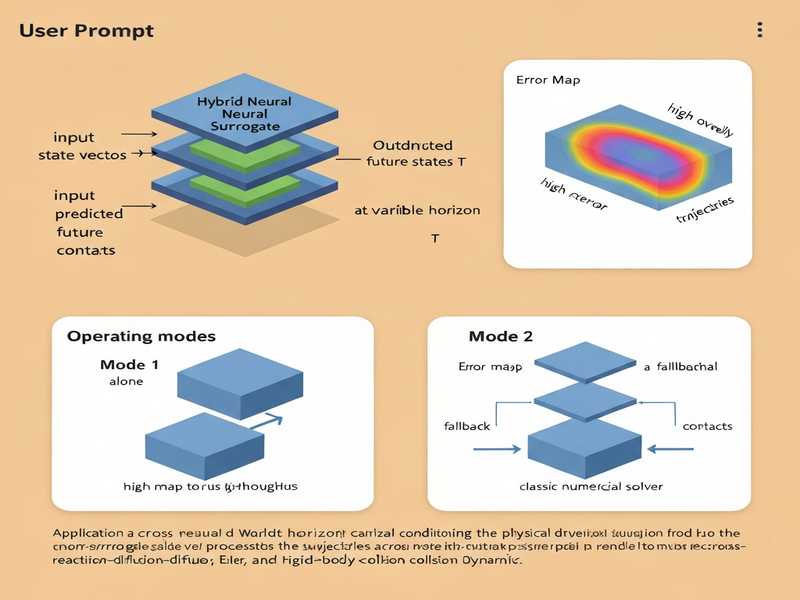
Background: Why This Problem Is Hard
Physical simulation underpins everything from aerospace design to real‑time game engines. Classical solvers—finite‑volume, finite‑difference, or spectral methods—are mathematically rigorous but computationally intensive, especially when the governing equations involve discontinuities such as shock waves or material interfaces. These sharp events demand fine spatial resolution and adaptive time‑stepping, inflating runtime by orders of magnitude.
Neural surrogates have emerged as a tempting alternative. By learning a mapping from current state to next state, they can replace costly numerical steps with a handful of matrix multiplications. However, existing surrogates suffer from two systemic weaknesses:
- Silent failure at discontinuities: The learned function is smooth by construction, so it cannot represent the abrupt jumps that characterize shocks or contact events. Errors accumulate unnoticed until the simulation diverges.
- Limited horizon flexibility: Most models are trained to predict a fixed number of steps ahead. Extending the horizon requires either recursive rollout (which compounds error) or retraining a new network for each horizon.
In safety‑critical domains—autonomous flight, nuclear safety, or high‑frequency trading—undetected errors are unacceptable. The industry therefore faces a trade‑off: retain the fidelity of textbook solvers or gamble on speed‑focused neural approximations that may break at the very moments they matter most.
What the Researchers Propose
The authors present a Hybrid Neural World Model (HNWM) that unifies two goals:
- Multi‑horizon prediction: A single network receives a continuous horizon parameter \(T\) and directly outputs the physical state at time \(t+T\). No recursion, no separate models.
- Implicit error localization: By comparing the network’s forward pass against a reference solver on a per‑trajectory basis, the system derives an error map that spikes precisely where shocks, fronts, or contacts occur.
Key components of the framework are:
- Continuous‑horizon conditioning module: Encodes the desired prediction horizon as a scalar that modulates the network’s latent dynamics.
- Physics‑agnostic backbone: A deep residual architecture that processes the full physical state (e.g., density, velocity, temperature) without embedding any governing‑equation knowledge.
- Error‑map extractor: A lightweight post‑processing step that aggregates per‑step residuals into a trajectory‑level confidence surface.
How It Works in Practice
Conceptual Workflow
The end‑to‑end pipeline can be broken into three stages:
- Data Generation: High‑resolution reference solvers (e.g., Godunov, MUSCL) produce ground‑truth trajectories across a diverse set of initial conditions and boundary configurations.
- Training with Horizon Supervision: Each training sample consists of \((\mathbf{s}_0, T, \mathbf{s}_T)\) where \(\mathbf{s}_0\) is the initial state, \(T\) the desired horizon, and \(\mathbf{s}_T\) the solver’s state at \(t+T\). The loss is a simple L2 distance; no explicit discontinuity labels are required.
- Inference & Error Mapping: At runtime, a user supplies \(\mathbf{s}_0\) and a horizon \(T\). The network returns \(\hat{\mathbf{s}}_T\). Simultaneously, the error‑map extractor computes a per‑cell residual by comparing \(\hat{\mathbf{s}}_T\) to a cheap, coarse‑grid reference or to an ensemble of stochastic forward passes. The resulting map highlights regions of high uncertainty.
Interaction Between Components
The horizon conditioning vector is concatenated with the state embedding before entering the residual blocks. This design forces the network to learn a continuous family of dynamics rather than a discrete set of time steps. The error‑map extractor operates downstream, requiring no additional training; it simply aggregates the magnitude of the network’s internal gradients or the variance across multiple stochastic forward passes. Because the error map is derived from the same forward pass, the system remains a single‑network solution—no ensembles, no auxiliary heads.
What Sets This Approach Apart
- Label‑free discontinuity detection: The model never sees shock locations during training, yet the error map reliably isolates them.
- Single‑network efficiency: Compared to deep ensembles or learned uncertainty heads, HNWM needs only one set of weights, reducing memory footprint and inference latency.
- Two operating modes:
- Mode 1 – Pure surrogate: Run the network alone for maximum throughput (26×–72× speedup on CPU).
- Mode 2 – Hybrid fallback: Use the error map to trigger a fallback to the textbook solver only on high‑uncertainty trajectories, cutting residual error roughly in half while preserving most of the speed gain.
Evaluation & Results
Testbed Scenarios
The authors benchmarked HNWM on three canonical PDE families:
- Reaction‑diffusion: FitzHugh‑Nagumo patterns with traveling fronts.
- Compressible Euler: Sod shock tube and blast wave problems featuring strong discontinuities.
- Rigid‑body collision dynamics: Multi‑body contact simulations with instantaneous impulse exchanges.
Key Findings
- Speed: In Mode 1, the surrogate achieved 26×–72× faster wall‑clock time than the reference solvers on identical CPU hardware.
- Accuracy: Across all domains, the mean absolute error (MAE) of the surrogate alone was comparable to deep ensembles and superior to gradient‑magnitude or conformal‑prediction baselines.
- Error‑map quality: The per‑trajectory error maps consistently peaked at shock fronts and contact interfaces, providing a reliable indicator for when to invoke the fallback solver.
- Hybrid mode benefit: By deferring only the top 20 % of uncertain trajectories to the reference solver, overall residual error dropped by roughly 50 % while preserving a net 30× speedup.
Why the Findings Matter
These results demonstrate that a single, horizon‑conditioned neural surrogate can replace a suite of specialized models without sacrificing the ability to detect and react to the most challenging dynamical events. The hybrid fallback strategy offers a pragmatic path for production systems that need both speed and safety guarantees.
Why This Matters for AI Systems and Agents
Hybrid Neural World Models open a new design space for AI‑driven simulation pipelines:
- Real‑time decision making: Autonomous agents can query the surrogate for rapid “what‑if” forecasts, then rely on the error map to request high‑fidelity verification only when the stakes are high.
- Scalable training environments: Reinforcement‑learning agents that learn in physics‑rich worlds (e.g., robotics, fluid control) can generate millions of rollouts per day, dramatically reducing compute budgets.
- Orchestration simplicity: Because the system is a single network plus a lightweight error extractor, it fits neatly into existing workflow automation tools such as the Workflow automation studio on UBOS.
- Enterprise integration: Companies building AI‑powered digital twins can embed the surrogate directly into their UBOS platform overview, leveraging the same API surface for both fast inference and fallback safety checks.
What Comes Next
While the Hybrid Neural World Model marks a significant step forward, several avenues remain open for exploration:
- Generalization to higher dimensions: Extending the approach to 3‑D turbulence or multi‑physics coupling (e.g., magnetohydrodynamics) will test the limits of horizon conditioning.
- Adaptive horizon selection: Future work could let the model itself propose an optimal \(T\) based on current uncertainty, turning the horizon into a learned control variable.
- Integration with probabilistic programming: Marrying the error map with Bayesian inference could yield calibrated uncertainty estimates suitable for risk‑aware planning.
- Hardware acceleration: Deploying the surrogate on GPUs, TPUs, or specialized inference chips could push speedups beyond the reported 72×, especially for large‑scale batch simulations.
Practitioners interested in prototyping these ideas can start by experimenting with UBOS’s OpenAI ChatGPT integration to orchestrate surrogate calls and fallback logic via natural‑language prompts. For teams focused on rapid market validation, the AI marketing agents showcase how a single neural model can power both content generation and performance monitoring, illustrating the broader applicability of hybrid surrogate concepts beyond pure physics.