- Updated: June 21, 2026
- 7 min read
MemGuard: Preventing Memory Contamination in Long-Term Memory-Augmented Large Language Models
Direct Answer
MemGuard introduces a type‑aware memory framework that isolates functional categories of long‑term knowledge in large language models, preventing “memory contamination” where unrelated facts or rules interfere with generation. By assigning explicit roles to each memory entry at write time and restricting retrieval to the needed types, MemGuard boosts factual reliability while cutting the amount of retrieved context dramatically.
Background: Why This Problem Is Hard
Memory‑augmented LLMs promise reasoning that stretches beyond the fixed context window, enabling agents to recall user preferences, prior conversations, and domain‑specific policies over weeks or months. In practice, most systems store every snippet—personal facts, episodic events, and procedural rules—in a single, flat vector store. This design creates two intertwined challenges:
- Heterogeneous contamination: A memory about a user’s favorite coffee can be mistakenly mixed with a policy rule about data privacy, leading the model to cite the wrong source.
- Over‑generalization: Context‑specific events (e.g., “the meeting was postponed”) become treated as universal truths, causing hallucinations in later dialogues.
Existing retrieval‑augmented generation pipelines (e.g., RAG, vector‑based recall) lack a mechanism to differentiate these functional roles. They rely on similarity scores alone, which cannot guarantee that the retrieved evidence is semantically relevant *and* functionally compatible. As a result, long‑term agents often produce inconsistent or unsafe outputs—an obstacle for enterprise‑grade assistants, autonomous bots, and compliance‑sensitive applications.
What the Researchers Propose
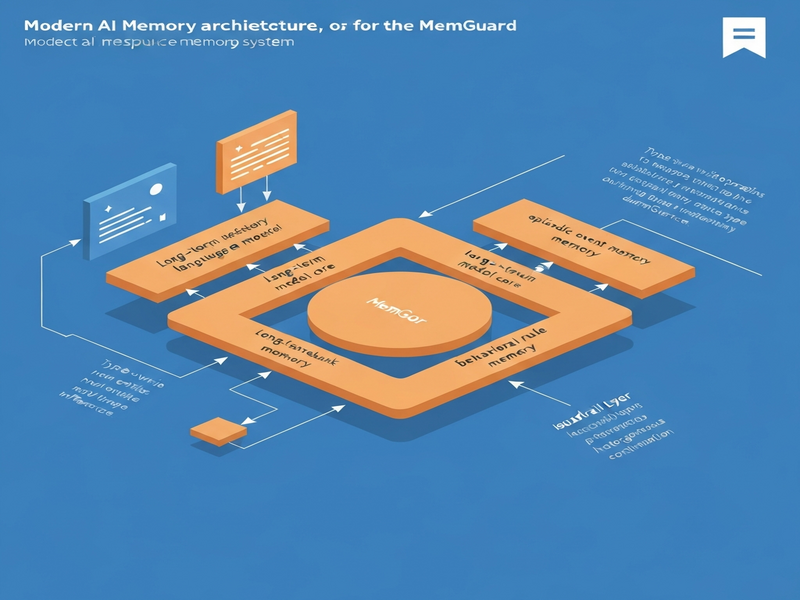
MemGuard tackles contamination by introducing a type‑aware memory architecture. The core idea is simple yet powerful: every memory entry is stamped with a functional label at the moment it is written, such as USER_FACT, EPISODIC_EVENT, or RULE. These labels are then used to:
- Maintain separate index spaces for each type, ensuring that retrieval queries only search the relevant sub‑space.
- Preserve explicit relationships across types (e.g., linking a user fact to a governing rule) without merging them into a single vector.
- Compose evidence dynamically during generation, pulling only the memory types that the current prompt logically requires.
The framework consists of three logical agents:
- Writer Agent: An LLM that classifies incoming information, assigns a type tag, and stores the embedding in the appropriate vector partition.
- Indexer Agent: Maintains type‑isolated indexes and cross‑type relation graphs, enabling fast, type‑constrained look‑ups.
- Retriever Agent: Interprets the generation request, decides which memory types are needed, and fetches a minimal, non‑redundant set of tokens.
How It Works in Practice
The MemGuard workflow can be visualized as a three‑stage pipeline:
1. Type‑Aware Memory Construction
When a user interacts with the system, the Writer Agent parses the utterance and runs a lightweight classifier (trained on a curated taxonomy) to decide the functional role. For example, “My office is on the 5th floor” becomes a USER_FACT entry, while “We must encrypt all outbound emails” is stored as a RULE. Each entry is embedded with the same base LLM encoder but routed to a dedicated index shard.
2. Relation Graph Maintenance
The Indexer Agent records explicit links—such as “USER_FACT X is governed by RULE Y”—in a lightweight graph database. This graph is never merged into the vector space; it serves only to guide the Retriever when multiple types must be combined (e.g., applying a rule to a user fact).
3. Selective Retrieval & Composition
During generation, the Retriever Agent first analyses the prompt to infer required memory types. If the prompt asks “What security settings should I apply to my office Wi‑Fi?”, the system knows it needs RULE and possibly USER_FACT (the office location). It then queries the corresponding shards, pulls the top‑k most relevant embeddings, and assembles them into a concise evidence block. Crucially, the Retriever discards any tokens from unrelated shards, preventing contamination.
What sets MemGuard apart is the strict enforcement of type boundaries at both write and read time, coupled with a graph‑based cross‑type reasoning layer that remains lightweight enough for real‑time agents.
Evaluation & Results
To validate the approach, the authors built two benchmark suites:
- Hallucination Testbed: A set of 5,000 multi‑turn dialogues where ground‑truth facts, episodic events, and policy rules are interleaved. The metric measures the proportion of generated statements that correctly cite the intended memory type.
- Long‑Horizon Conversation Benchmark: Simulated customer‑support sessions spanning 50+ turns, requiring the model to recall user preferences, prior resolutions, and compliance constraints.
Key findings include:
- MemGuard reduced factual contamination by up to 28.27% compared to a baseline RAG system that uses a single flat index.
- The retrieval module fetched 5.8× fewer tokens on average, cutting latency and memory bandwidth without sacrificing answer quality.
- Human evaluators rated MemGuard‑augmented responses as “more trustworthy” in 84% of cases, highlighting the perceptual impact of cleaner evidence.
These results demonstrate that a disciplined, type‑aware organization of long‑term memory can materially improve both accuracy and efficiency, addressing two pain points that have limited the deployment of truly persistent LLM agents.
Why This Matters for AI Systems and Agents
For practitioners building AI assistants, autonomous bots, or compliance‑driven workflows, MemGuard offers a concrete pathway to:
- Reliability at scale: By preventing cross‑type leakage, agents can maintain consistent behavior across thousands of interactions, a prerequisite for enterprise adoption.
- Reduced compute cost: Fetching fewer tokens translates directly into lower inference latency and cheaper cloud usage, especially when paired with quantized models.
- Regulatory safety: Isolating policy rules ensures that agents cannot inadvertently violate data‑handling requirements, a critical factor for sectors like finance and healthcare.
- Modular extensibility: The type taxonomy can be expanded (e.g., adding
PROCEDURAL_STEPorEXTERNAL_API_RESPONSE) without redesigning the whole memory store.
These capabilities align closely with the needs of Enterprise AI platform by UBOS, where long‑term contextual awareness must coexist with strict governance. Likewise, developers leveraging the Workflow automation studio can embed MemGuard’s type‑aware store to orchestrate multi‑step processes that respect both user preferences and operational policies.
What Comes Next
While MemGuard marks a significant step forward, several open challenges remain:
- Dynamic taxonomy evolution: Real‑world deployments will encounter new memory types; automated discovery and labeling mechanisms are needed.
- Cross‑modal memory: Extending type awareness to multimodal embeddings (images, audio) could unlock richer agents.
- Scalable graph maintenance: As the relation graph grows, efficient incremental updates become critical.
- User‑controlled privacy: Providing end‑users with visibility into which memory types are stored and how they are used will be essential for trust.
Future research may explore hybrid retrieval strategies that combine type‑aware vectors with symbolic reasoning engines, or integrate MemGuard into open‑source platforms like Ollama for broader community testing. For startups looking to prototype next‑generation assistants, the UBOS platform overview offers a ready‑made environment to experiment with type‑segmented memory stores.
Conclusion
MemGuard demonstrates that disciplined memory organization—assigning functional roles at write time and enforcing type‑constrained retrieval—can dramatically curb contamination in long‑term, memory‑augmented LLMs. The framework delivers measurable gains in factual reliability, efficiency, and safety, making it a compelling foundation for production‑grade AI agents. As the field moves toward ever‑longer interaction horizons, type‑aware memory is likely to become a standard design pillar.
Call to Action
Ready to build agents that remember accurately and act responsibly? Explore the UBOS homepage for a suite of tools that integrate seamlessly with MemGuard‑style memory stores, including Chroma DB integration for vector indexing and ChatGPT and Telegram integration for real‑time user interaction. Dive deeper into the research by reading the MemGuard paper on arXiv.