- Updated: June 20, 2026
- 5 min read
Multi-Teacher Knowledge Distillation via Teacher-Informed Mixture Priors
Direct Answer
The paper introduces Multi‑Teacher Bayesian Knowledge Distillation (MT‑BKD), a framework that lets a compact student model learn from several large teachers while explicitly modeling uncertainty through Bayesian inference. This matters because it gives practitioners a principled way to compress powerful models, combine diverse expertise, and obtain reliable confidence estimates for downstream decisions.
Background: Why This Problem Is Hard
Deploying state‑of‑the‑art deep networks—especially large language models (LLMs) and vision transformers—remains expensive in terms of compute, memory, and latency. Knowledge distillation (KD) has become the go‑to technique for shrinking models, but most existing KD pipelines suffer from three critical gaps:
- Single‑teacher bias: Traditional KD assumes one teacher, ignoring the fact that real‑world applications often have multiple specialists (e.g., a language model for syntax, another for domain jargon).
- Lack of uncertainty quantification: Distilled students inherit the teacher’s predictions as hard targets, providing no measure of confidence—a liability for safety‑critical domains like healthcare or autonomous driving.
- Static weighting of teachers: When teachers disagree, naïve averaging can dilute valuable signals, leading to sub‑optimal student performance.
These shortcomings limit the reliability and scalability of KD in production AI systems, where diverse expertise and trustworthy predictions are non‑negotiable.
What the Researchers Propose
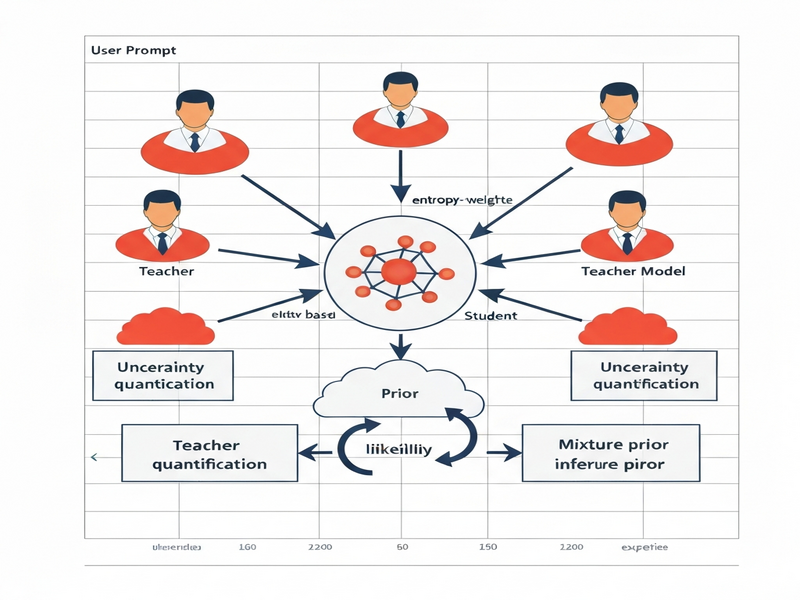
MT‑BKD reframes distillation as a Bayesian learning problem. Instead of treating teacher outputs as fixed labels, the framework treats them as probabilistic sources that shape a teacher‑informed prior over the student’s parameters. The key components are:
- Teacher‑Informed Mixture Prior: A prior distribution that blends knowledge from each teacher, weighted by an entropy‑based relevance score.
- Entropy‑Based Teacher Weighting: Dynamically adjusts each teacher’s influence based on the certainty of its predictions for a given input.
- Bayesian Posterior Update: The student’s parameters are updated via variational inference, preserving a distribution rather than a point estimate.
Collectively, these elements let the student model inherit the strengths of multiple teachers while maintaining a calibrated uncertainty estimate.
How It Works in Practice
The MT‑BKD workflow can be visualized as a three‑stage pipeline:
- Prior Construction: For each training sample, every teacher produces a soft prediction (logits or probability vector). The system computes the entropy of each prediction; lower entropy indicates higher confidence. These entropies are transformed into weights that blend the teachers into a mixture prior.
- Variational Inference Loop: The student model, initialized with the mixture prior, processes the same input. Using a variational objective that balances data likelihood with KL‑divergence to the prior, the student’s posterior distribution is refined.
- Uncertainty‑Aware Prediction: At inference time, the student draws samples from its posterior to produce a predictive distribution. The variance across samples serves as a built‑in confidence measure.
What sets MT‑BKD apart is the feedback loop between teacher certainty and student learning: teachers that are more certain for a particular instance exert stronger pull on the student’s posterior, while uncertain teachers contribute less, preventing noise amplification.
Evaluation & Results
The authors validated MT‑BKD on two domains:
- Protein subcellular location prediction: A bio‑informatics task where multiple specialized models (sequence‑based, structure‑based) provide complementary cues.
- Image classification (CIFAR‑100): A standard vision benchmark using three heterogeneous teachers (ResNet‑50, EfficientNet‑B3, Vision Transformer).
Key findings include:
- The MT‑BKD student consistently outperformed single‑teacher KD baselines by 2–4% absolute accuracy.
- Uncertainty calibration, measured via Expected Calibration Error (ECE), improved by up to 35%, indicating more trustworthy confidence scores.
- When one teacher was deliberately corrupted (e.g., noisy labels), the entropy‑based weighting automatically reduced its impact, preserving overall performance.
These results demonstrate that MT‑BKD not only compresses models effectively but also endows the distilled student with robust, interpretable uncertainty—critical for real‑world deployment.
Why This Matters for AI Systems and Agents
For practitioners building AI agents, MT‑BKD offers three practical advantages:
- Modular Expertise Integration: Agents can ingest specialized teachers (e.g., a legal‑domain LLM, a financial‑forecasting model) and produce a unified, lightweight decision engine.
- Risk‑Aware Automation: The built‑in uncertainty estimates enable agents to trigger fallback mechanisms—such as human‑in‑the‑loop review—when confidence drops below a threshold.
- Scalable Deployment: By compressing multiple large models into a single student, infrastructure costs shrink, making edge‑oriented AI agents feasible.
Enterprises looking to operationalize AI at scale can embed MT‑BKD within their UBOS platform overview, leveraging the platform’s orchestration layer to manage teacher pools and automate posterior updates. The result is a more agile AI stack that balances performance, cost, and safety.
What Comes Next
While MT‑BKD marks a significant step forward, several avenues remain open:
- Dynamic Teacher Discovery: Future work could let the system automatically recruit new teachers from a model zoo based on task similarity.
- Continual Learning: Extending the Bayesian posterior to accommodate streaming data would keep the student up‑to‑date without retraining from scratch.
- Cross‑Modal Distillation: Applying MT‑BKD to fuse vision, language, and audio teachers could power multimodal agents for robotics or virtual assistants.
From a product perspective, developers can prototype these ideas using the Workflow automation studio to script teacher selection, prior construction, and posterior inference. Startups may find the UBOS for startups tier especially attractive for rapid experimentation, while larger firms can scale to the Enterprise AI platform by UBOS for production‑grade workloads.
Conclusion
Multi‑Teacher Bayesian Knowledge Distillation reframes model compression as a probabilistic synthesis of diverse expertise, delivering higher accuracy, calibrated uncertainty, and resilience to noisy teachers. By embedding these capabilities into modern AI pipelines—whether for bio‑informatics, computer vision, or large‑scale language agents—organizations can achieve faster, cheaper, and safer inference. The open research questions around dynamic teacher management and continual learning promise a fertile ground for the next generation of intelligent, uncertainty‑aware agents.
For a deeper dive into the methodology and experimental details, consult the original Multi-Teacher Knowledge Distillation paper.