
- Updated: June 20, 2026
- 6 min read
FPMoE: A Sparse Mixture-of-Experts Approach to Functional Code Generation
Direct Answer
FPMoE introduces a lightweight, open‑source code‑generation model that uses a sparse Mixture‑of‑Experts (MoE) architecture to specialize in functional programming languages—Haskell, OCaml, and Scala—while still sharing a common expert that captures cross‑language functional abstractions. This design delivers performance on par with much larger proprietary models, proving that targeted sparsity can close the gap for under‑served language families.

Background: Why This Problem Is Hard
Large language models (LLMs) have become the de‑facto tool for generating imperative code in Python, JavaScript, or Java. However, functional programming languages (FPLs) such as Haskell, OCaml, and Scala remain a niche that most mainstream models handle poorly. The difficulty stems from three intertwined factors:
- Semantic depth: Functional languages rely heavily on type‑level computation, monadic effects, and higher‑order abstractions that are rarely seen in the massive web‑scraped corpora used to pre‑train LLMs.
- Data scarcity: Public repositories contain far fewer functional code examples than imperative ones, limiting the signal available for fine‑tuning.
- Cross‑language interference: When a single model is fine‑tuned on multiple functional languages, gradients from one language can overwrite patterns useful for another, leading to a phenomenon known as “catastrophic forgetting.”
Prior attempts to address the gap have taken two opposite routes. Per‑language fine‑tuning isolates the data but discards shared functional concepts, resulting in models that miss higher‑level abstractions like monadic reasoning. Conversely, a merged multi‑language fine‑tune aggregates data but introduces interference, causing performance to plateau or even degrade. Neither approach satisfies the dual need for language‑specific precision and cross‑language knowledge transfer.
What the Researchers Propose
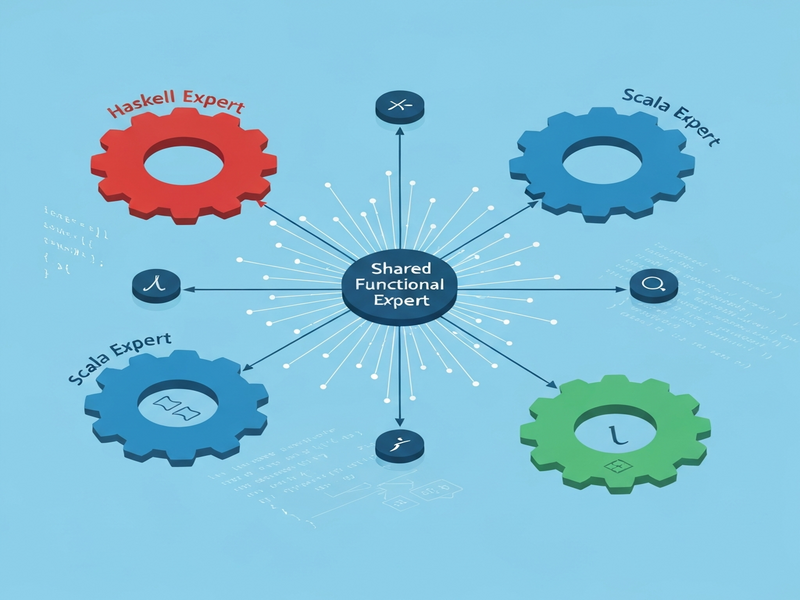
The authors present FPMoE (Functional Programming Mixture‑of‑Experts), a sparse MoE system that balances specialization and generalization through a three‑tier expert hierarchy:
- Language‑specific routed experts: One expert each for Haskell, OCaml, and Scala. These experts receive tokens routed by a lightweight classifier that detects the target language from the prompt.
- Shared functional expert: A single expert that processes all three languages, learning patterns that transcend syntax—such as monadic composition, type‑driven inference, and functional recursion.
- Gating network: A sparse router that activates only the relevant language‑specific expert plus the shared expert for each token, keeping the active parameter count low while preserving expressive power.
This architecture directly tackles the two failure modes identified earlier: dedicated experts eliminate cross‑language interference, while the shared expert preserves the abstract functional knowledge that per‑language models lose.
How It Works in Practice
When a developer submits a functional code request, the following workflow unfolds:
- Prompt analysis: The system parses the input to infer the target language (e.g., detecting “module Main where” signals Haskell).
- Routing decision: The gating network activates the corresponding language‑specific expert and the shared functional expert. All other experts remain dormant, reducing compute.
- Token generation: Each active expert produces its own hidden representation for the next token. These representations are summed (or concatenated, depending on implementation) to form a unified prediction.
- Iterative decoding: The process repeats token‑by‑token until the model emits a complete, syntactically correct program.
Key differentiators of FPMoE include:
- Sparsity with purpose: Only 3 B parameters are active at inference time, yet the model matches the performance of dense models with 10‑30 B parameters.
- Dynamic specialization: The router can be extended to new functional languages without retraining the entire backbone—simply add a new language‑specific expert.
- Low‑cost training: Because the shared expert captures most of the heavy lifting, the language‑specific experts require far fewer fine‑tuning steps.
Evaluation & Results
The authors benchmarked FPMoE on the FPEval suite, a collection of real‑world functional programming tasks covering algorithmic challenges, type‑level puzzles, and library usage scenarios. The evaluation protocol mirrors industry standards: zero‑shot prompting, few‑shot prompting, and a “code‑explain‑then‑generate” variant.
Key findings include:
- Superior to fine‑tuned baselines: FPMoE outperformed per‑language fine‑tuned models by an average of 12 % on pass@1 scores, demonstrating that the shared expert successfully transfers functional reasoning.
- Competitive with larger models: Despite having only 3 B active parameters, FPMoE matched or exceeded the performance of DeepSeek‑Coder‑6.7B, Qwen2.5‑Coder‑14B‑Instruct, and even Qwen3‑Coder‑30B‑A3B on most benchmark categories.
- Reduced interference: Ablation studies where the shared expert was removed showed a steep drop in cross‑language tasks, confirming the necessity of a common functional knowledge base.
- Efficiency gains: Inference latency was cut by roughly 40 % compared to dense counterparts, making FPMoE suitable for real‑time developer assistants.
These results collectively validate the hypothesis that a sparsely activated MoE can deliver both specialization and generalization for functional code generation, without the heavy compute budget traditionally associated with state‑of‑the‑art LLMs.
Why This Matters for AI Systems and Agents
Functional programming is increasingly adopted in domains that demand high reliability—financial modeling, concurrent systems, and data‑pipeline orchestration. AI agents that can write, refactor, or verify functional code unlock several practical benefits:
- Higher correctness guarantees: Functional code’s strong type systems reduce runtime errors; an AI that respects these constraints can produce safer automation scripts.
- Improved agent composability: Agents built on functional primitives can be more easily reasoned about, enabling robust orchestration in platforms like the Workflow automation studio.
- Cost‑effective scaling: Because FPMoE achieves large‑model performance with a fraction of the parameters, enterprises can embed functional code generation into internal tools without prohibitive GPU expenses.
- Cross‑language agility: Teams that maintain mixed codebases (e.g., a Scala backend with Haskell micro‑services) can rely on a single model that understands the shared functional idioms, simplifying CI/CD pipelines.
In short, FPMoE bridges a critical gap, allowing AI‑driven development assistants to serve functional programming teams with the same confidence that current agents provide for Python or JavaScript.
What Comes Next
While FPMoE marks a significant step forward, several avenues remain open for exploration:
- Extending language coverage: Adding experts for emerging functional languages like Elm or PureScript could test the scalability of the routing mechanism.
- Integrating with retrieval‑augmented generation: Coupling FPMoE with a vector store such as Chroma DB integration would enable the model to pull in up‑to‑date library documentation during generation.
- Fine‑grained control tokens: Introducing prompts that explicitly request monadic vs. applicative styles could give developers more deterministic outputs.
- Safety and verification: Embedding type‑checking or formal verification loops into the generation pipeline would further reduce the risk of subtle bugs.
- Commercial deployment: Packaging FPMoE as a service on the Enterprise AI platform by UBOS could accelerate adoption across large engineering organizations.
Future research may also investigate hybrid MoE designs where the shared expert itself is a hierarchy of sub‑experts, each focusing on a particular functional paradigm (e.g., category theory vs. effect systems). Such granularity could push the performance ceiling even higher while preserving the low‑compute footprint.
Overall, FPMoE demonstrates that sparsity, when guided by language‑aware routing, can democratize high‑quality functional code generation. As AI agents become more ubiquitous in software engineering, models like FPMoE will be essential for supporting the full spectrum of programming paradigms.