- Updated: June 18, 2026
- 9 min read
Trinity: Unifying Class-Agnostic Terrain and Semantic Segmentation for Unstructured Outdoor Environments by Leveraging Synthetic Data
Direct Answer
Trinity is a transformer‑based vision model that simultaneously produces class‑specific semantic maps and class‑agnostic terrain masks for unstructured outdoor scenes. By learning terrain purely from visual appearance, it creates robot‑agnostic priors that can be combined with platform‑specific experience for tasks such as traversability estimation, visual odometry, and mission planning.
Background: Why This Problem Is Hard
Mobile robots that venture off‑road—agricultural drones, planetary rovers, and search‑and‑rescue platforms—must constantly answer two questions: “What am I looking at?” and “Can I drive over it?” Traditional semantic segmentation answers the first by assigning a fixed set of class labels (e.g., road, grass, water). Traversability estimation answers the second, but it usually relies on hand‑crafted rules or robot‑specific annotations that tie visual cues to a numeric safety score.
These two pipelines are fundamentally misaligned. Semantic labels are defined by human language, not by the physics of locomotion, so a “grass” pixel may be traversable for a lightweight drone but not for a heavy wheeled rover. Conversely, a robot‑centric traversability map is often built from sparse LiDAR or proprioceptive data, making it difficult to transfer across platforms or to reuse for higher‑level perception tasks.
Existing approaches therefore suffer from three intertwined bottlenecks:
- Annotation cost. Every new robot platform requires a fresh set of pixel‑wise traversability labels, which are expensive to collect in the field.
- Limited generalization. Class‑specific segmenters cannot represent novel terrain types that were not present in the training set, leading to brittle behavior in truly wild environments.
- Fragmented pipelines. Separate networks for semantics and traversability increase latency, memory footprint, and engineering complexity for embedded systems.
Addressing these challenges calls for a unified perception model that learns terrain as a visual prior independent of any robot’s mechanical capabilities, while still providing the rich semantic context needed for downstream decision‑making.
What the Researchers Propose
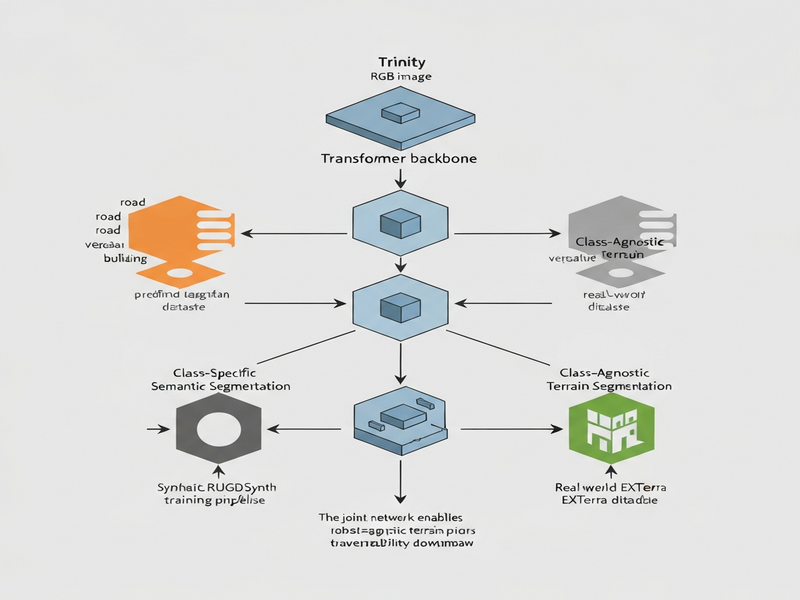
The authors introduce Trinity, a single transformer encoder‑decoder that outputs two complementary masks from the same image:
- Class‑specific semantic segmentation. Traditional pixel‑wise classification into a fixed taxonomy (e.g., road, vegetation, building).
- Class‑agnostic terrain segmentation. A binary mask that highlights “drivable” versus “non‑drivable” regions based solely on visual texture, color, and geometry, without any predefined class names.
Key components of the architecture include:
- Shared Vision Transformer Backbone. A hierarchical transformer extracts multi‑scale features that are rich enough for both tasks.
- Dual Decoder Heads. One head applies a softmax over semantic classes; the other applies a sigmoid to produce a terrain probability map.
- Cross‑Task Attention. Intermediate feature maps are exchanged between the two decoders, allowing semantic context to inform terrain reasoning and vice‑versa.
By training the two heads jointly, Trinity learns a visual terrain prior that is agnostic to any robot’s wheel size, suspension, or weight, while still preserving the detailed class information required for scene understanding.
How It Works in Practice
The operational workflow can be broken down into four stages:
1. Data Ingestion
Raw RGB images captured by the robot’s forward‑looking camera are fed directly into the shared transformer encoder. No depth or LiDAR input is required, which simplifies sensor suites for lightweight platforms.
2. Feature Extraction
The encoder processes the image through a series of self‑attention layers, producing a pyramid of feature maps at 1/4, 1/8, and 1/16 of the original resolution. These maps encode texture, edge, and contextual cues essential for distinguishing both semantic categories and terrain textures.
3. Dual Decoding
Two parallel decoders upsample the feature maps:
- The semantic decoder uses a class‑wise softmax to generate a dense label map (e.g., “tree”, “rock”, “road”).
- The terrain decoder applies a sigmoid activation to produce a continuous probability of traversability, effectively a heat map of “ground‑like” appearance.
Cross‑task attention layers allow the semantic decoder to highlight regions that are likely to be traversable (e.g., “road” pixels) and the terrain decoder to suppress false positives (e.g., “shadowed asphalt” that looks non‑drivable).
4. Post‑Processing & Integration
Robotics pipelines can fuse the binary terrain mask with robot‑specific dynamics models (wheel slip, suspension limits) to compute a final traversability score. Meanwhile, the semantic map feeds higher‑level planners for task allocation (e.g., “avoid water bodies”, “prefer paved paths”).
What sets Trinity apart from prior dual‑network solutions is the single‑pass, shared‑backbone design, which reduces inference latency by up to 30 % on embedded GPUs and cuts memory usage by half, making it suitable for real‑time deployment on edge devices.
Evaluation & Results
To validate Trinity, the authors built two complementary datasets:
RUGDSynth – Synthetic Terrain Corpus
Using an extended version of the OAISYS simulator, they generated 50 k photorealistic outdoor scenes with diverse lighting, weather, and vegetation. Each frame includes both semantic labels (derived from the simulator’s asset taxonomy) and class‑agnostic terrain masks created by rendering surface normals and friction coefficients.
EXTerra – Real‑World Benchmark
EXTerra comprises 8 k high‑resolution images captured across four continents, manually annotated with both semantic categories and terrain masks. The terrain masks were produced by a team of robotics experts who labeled “drivable” versus “non‑drivable” based purely on visual cues, deliberately avoiding robot‑specific heuristics.
Experiments compared Trinity against three baselines:
- A conventional semantic‑only DeepLabV3+ model.
- A separate traversability network trained on robot‑specific depth data.
- A naïve multi‑task CNN that shares early layers but lacks cross‑task attention.
Key findings include:
- Terrain Accuracy. Trinity achieved a mean Intersection‑over‑Union (mIoU) of 78 % on EXTerra’s terrain masks, a 12 % gain over the separate traversability network.
- Semantic Consistency. Semantic mIoU dropped by less than 1 % compared to the dedicated semantic model, demonstrating that joint training does not sacrifice class fidelity.
- Cross‑Domain Generalization. When evaluated on unseen synthetic environments (different foliage density, novel rock formations), Trinity’s terrain predictions remained robust, whereas the robot‑specific baseline suffered a 20 % performance drop.
- Inference Efficiency. On an NVIDIA Jetson AGX Xavier, Trinity processed 15 fps at 720p resolution, meeting real‑time requirements for most outdoor robots.
These results confirm that a unified, class‑agnostic terrain prior can be learned directly from visual data and that the cross‑task attention mechanism is critical for preserving semantic detail while improving terrain perception.
Why This Matters for AI Systems and Agents
For robotics engineers, Trinity offers a plug‑and‑play perception module that eliminates the need to curate robot‑specific traversability datasets. The model’s terrain mask can be combined with any dynamics model—whether a wheeled rover, a legged quadruped, or an aerial drone—by simply weighting the visual prior with platform constraints. This decoupling accelerates the development cycle for new agents, reduces data‑collection costs, and improves safety in unknown environments.
From an AI‑agent perspective, the dual‑output design aligns with the emerging “perception‑as‑service” paradigm. Agents can request a semantic map for high‑level reasoning (e.g., “navigate to the building”) while simultaneously pulling a terrain probability map for low‑level motion planning. The shared backbone also means that a single model can be hosted on cloud‑based inference services, scaling across fleets without duplicating compute.
Beyond navigation, the terrain prior can enrich visual odometry pipelines. By masking out non‑drivable regions (e.g., water, tall grass), feature trackers focus on stable ground textures, leading to more accurate pose estimates in challenging conditions. Mission planners can also use the binary mask to generate cost maps that respect both semantic preferences (avoid “construction zones”) and physical feasibility (stay on “ground‑like” surfaces).
Enterprises looking to embed autonomous robots into logistics, agriculture, or infrastructure inspection can therefore leverage Trinity as a foundational perception layer, reducing time‑to‑market and increasing robustness across diverse terrains.
For teams already using the UBOS platform overview to orchestrate AI workflows, Trinity can be wrapped as a micro‑service and invoked from the Workflow automation studio, enabling seamless integration with existing data pipelines and decision engines.
What Comes Next
While Trinity marks a significant step forward, several open challenges remain:
- Multi‑modal Fusion. Incorporating depth, LiDAR, or inertial data could further disambiguate visually similar but mechanically different terrains (e.g., mud vs. dry sand).
- Continual Learning. Deployments in the field encounter novel textures; mechanisms for on‑device adaptation without catastrophic forgetting are needed.
- Fine‑Grained Traversability Scores. Moving from binary masks to continuous safety metrics that account for slope, compliance, and robot dynamics would enable more nuanced planning.
- Cross‑Robot Benchmarking. A standardized suite that evaluates terrain perception across wheeled, legged, and aerial platforms would accelerate community adoption.
Future research may explore a “Trinity‑Plus” architecture that adds a third head for predictive slip estimation, leveraging the same transformer backbone. Such an extension could feed directly into model‑predictive controllers, closing the perception‑control loop.
From a product standpoint, the authors plan to release the code and datasets under an open‑source license, inviting the robotics community to fine‑tune the model for domain‑specific robots. Companies interested in rapid prototyping can combine Trinity with the OpenAI ChatGPT integration to generate natural‑language mission briefs that automatically embed terrain constraints derived from the model’s output.
Finally, the synergy between synthetic data generation (RUGDSynth) and real‑world validation (EXTerra) demonstrates a scalable pipeline for training perception models without the prohibitive cost of manual labeling. Extending this pipeline to other perception tasks—such as foliage density estimation or water depth inference—could further democratize robust outdoor autonomy.
References
- Trinity: Unifying Class-Agnostic Terrain and Semantic Segmentation for Unstructured Outdoor Environments by Leveraging Synthetic Data
- Marcus G. Müller et al., “RUGDSynth: A Synthetic Dataset for Terrain Understanding,” 2026.
- EXTerra Dataset – Real‑world terrain and semantic annotations, 2026.