- Updated: June 18, 2026
- 6 min read
Eliot: Interactively $\underline{E}$xploring Fast-Changing Scientific $\underline{Li}$terature Trends with $\underline{O}$nline Da$\underline{t}$a and Learning
Direct Answer
Eliot is an interactive web system that lets researchers query arXiv in real time, automatically clusters the retrieved papers into thematic groups, and visualizes how each theme evolves over calendar years. By surfacing temporal patterns without hidden preprocessing, Eliot gives scholars an auditable, up‑to‑date view of fast‑moving scientific domains.
Background: Why This Problem Is Hard
The volume of scientific output has exploded: arXiv alone adds more than 10,000 new submissions each week across dozens of sub‑fields. Traditional literature‑search tools excel at keyword matching but fall short when users need to understand how a field is shifting over time. Two intertwined challenges make this problem especially tough:
- Opaque corpus construction. Search engines and LLM‑based assistants often rely on static snapshots or opaque ranking pipelines, leaving users blind to selection bias or temporal gaps.
- Lack of dynamic thematic grouping. Hand‑crafted taxonomies cannot keep pace with emerging sub‑topics, and batch clustering pipelines become stale as new papers appear.
Consequently, researchers waste hours manually scanning abstracts, building ad‑hoc spreadsheets, or trusting black‑box summaries that hide the evidence behind observed trends. A solution that combines on‑demand retrieval, transparent clustering, and year‑wise visual inspection is therefore a critical missing piece in the scholarly workflow.
What the Researchers Propose
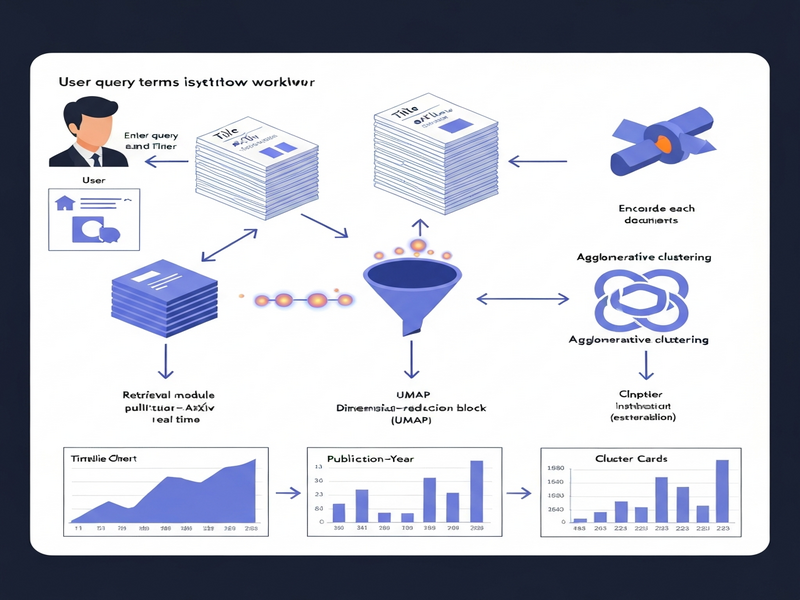
The authors introduce Eliot, a query‑time literature‑exploration framework that replaces static taxonomies with live, data‑driven clustering. The system consists of three logical components:
- Retrieval Engine. Given a user‑specified query (keywords, author names, or arXiv categories) and optional filters (date range, subject area), the engine pulls the latest matching papers directly from the arXiv API.
- Semantic Representation Layer. Each paper’s title and abstract are encoded using MiniLM embeddings, a lightweight transformer model that captures nuanced meaning while remaining computationally efficient.
- Temporal Clustering & Visualization Module. The embeddings are reduced to a 10‑dimensional space with UMAP, then grouped by Agglomerative Clustering. Each cluster receives a set of representative keywords, and a histogram of publication years is rendered for quick trend spotting.
By chaining these components at query time, Eliot guarantees that every visual insight reflects the most recent corpus, and that the clustering logic is fully reproducible.
How It Works in Practice
The user journey can be broken down into a clear, repeatable workflow:
- Define a research question. The user enters a free‑text query such as “large language model alignment” and selects optional filters (e.g., “Computer Science – AI”).
- Live retrieval. Eliot calls the arXiv API, pulls up to several thousand matching records, and stores the title‑abstract pairs in memory.
- Embedding generation. Each document is passed through a pre‑trained MiniLM model, producing a dense vector that captures semantic similarity.
- Dimensionality reduction. UMAP compresses the high‑dimensional vectors to a 10‑D manifold, preserving local neighborhood structure essential for clustering.
- Cluster formation. Agglomerative (bottom‑up) clustering merges the most similar vectors until a predefined silhouette‑score threshold is met, yielding a set of coherent themes.
- Label extraction. For each cluster, the system extracts the top‑N TF‑IDF weighted terms from the constituent abstracts, presenting them as human‑readable labels.
- Temporal charting. A bar chart shows the count of papers per year for each cluster, allowing the user to spot emerging spikes or declining interest.
- Iterative refinement. Users can click a cluster to drill down, adjust the query, or re‑run the pipeline with a different number of clusters, instantly seeing updated visualizations.
What sets Eliot apart is the on‑the‑fly nature of every step. No pre‑computed index, no hidden batch jobs, and no static taxonomy. The entire pipeline runs in under a minute on a modest cloud VM, making it suitable for daily exploratory sessions.
Evaluation & Results
The authors validated Eliot from two angles: a systematic configuration study across eight arXiv domains, and a user‑centric scenario‑based survey with domain experts.
Configuration Study
They compared three embedding families (MiniLM, SciBERT, and Sentence‑BERT), three dimensionality‑reduction techniques (PCA, t‑SNE, UMAP), and four clustering algorithms (K‑Means, DBSCAN, Agglomerative, Spectral). Two objective metrics guided the selection:
- Intrinsic clustering quality measured by silhouette score.
- Topic coherence assessed via normalized pointwise mutual information (NPMI) on cluster keywords.
The results consistently favored MiniLM embeddings paired with 10‑dimensional UMAP and Agglomerative Clustering, achieving the highest silhouette (≈0.42) and NPMI (≈0.31) across domains such as Machine Learning, Quantum Physics, and Automated Planning. This configuration balances semantic fidelity with computational speed, justifying its adoption as the default pipeline.
User Study
In a scenario‑based survey, 24 participants—including senior researchers in LLMs and APS—were asked to explore three fast‑changing topics using Eliot. They rated cluster labels as “meaningful” in 85 % of responses and highlighted the temporal histogram as the most valuable visual cue for spotting nascent sub‑fields. A follow‑up focus group emphasized that Eliot’s auditability—being able to trace a trend back to the exact papers that generated it—filled a gap left by conventional search engines.
Overall, the evaluation demonstrates that Eliot not only produces statistically sound clusters but also delivers actionable insights that users trust and can act upon.
Why This Matters for AI Systems and Agents
For AI practitioners building agents that need up‑to‑date domain knowledge, Eliot offers a plug‑and‑play knowledge‑extraction layer. Instead of hard‑coding static corpora, an autonomous system can invoke Eliot’s API to:
- Refresh its knowledge base. Pull the latest thematic clusters before answering a user query, ensuring recommendations reflect the newest research.
- Generate evidence‑backed explanations. Cite the specific papers that underpin a trend, improving transparency and trustworthiness of AI‑driven recommendations.
- Detect emerging risks. Spot sudden spikes in clusters related to safety, bias, or regulation, allowing agents to flag potential compliance concerns.
These capabilities align directly with the needs of Enterprise AI platform by UBOS, where dynamic literature feeds can enrich decision‑support modules, automated report generators, and compliance monitors.
What Comes Next
While Eliot marks a significant step forward, several avenues remain open for research and productization:
- Scalability to multimodal corpora. Extending the pipeline to ingest full‑text PDFs, code repositories, or video abstracts would broaden coverage beyond titles and abstracts.
- User‑guided clustering. Allowing domain experts to seed clusters with seed terms or to merge/split clusters interactively could improve relevance for niche sub‑fields.
- Cross‑archive federation. Integrating other pre‑print servers (e.g., bioRxiv, HAL) would enable cross‑disciplinary trend detection.
- Automated alerting. Building a subscription service that notifies users when a cluster’s yearly count exceeds a growth threshold could turn Eliot into a proactive monitoring tool.
Addressing these challenges will push Eliot from a research prototype toward a production‑grade component of AI‑augmented knowledge work. Organizations interested in embedding such capabilities can explore the broader UBOS platform overview for modular integration options.
References