
- Updated: June 10, 2026
- 8 min read
Asking Is Not Enough: Protocol Sensitivity in LLM Confidence Calibration
Direct Answer
The paper “Asking Is Not Enough: Protocol Sensitivity in LLM Confidence Calibration” reveals that the apparent superiority of verbalized confidence over token‑probability scores is highly dependent on experimental protocols—specifically the choice of answer string, token‑readout method, and conditioning context. In practice, this means that confidence metrics cannot be treated as universal readouts; they must be reported with a full protocol description.
Background: Why This Problem Is Hard
Large language models (LLMs) are increasingly deployed as decision‑support agents, chat assistants, and autonomous planners. In these settings, a model’s confidence estimate is often the only signal that downstream systems use to decide whether to act, defer to a human, or request more information. Two dominant confidence signals have emerged:
- Token‑probability scores: the raw probability the model assigns to the next token(s) during generation.
- Verbalized confidence: a natural‑language statement (e.g., “I am 85% sure”) produced after a dedicated prompt.
Both signals are attractive because they are easy to extract and appear to map directly onto model uncertainty. However, the research community has largely treated them as interchangeable “ground‑truth” measures, overlooking the fact that each requires a series of design choices—prompt templates, probability scales, answer formatting, and the context in which the model is queried. These hidden choices can dramatically shift calibration outcomes, leading to misleading conclusions about model reliability.
Existing evaluation pipelines typically:
- Generate an answer with a single prompt.
- Read the probability of the first token or the entire answer string.
- Compare the resulting Expected Calibration Error (ECE) against a verbalized confidence score.
This workflow assumes that the “answer string” is uniquely defined and that the probability readout is invariant to tokenization quirks. In reality, LLMs often produce multiple plausible surface forms, and token‑level probabilities can fluctuate based on subtle context changes. The lack of a standardized protocol makes cross‑paper comparisons fragile and hampers reproducibility.
What the Researchers Propose
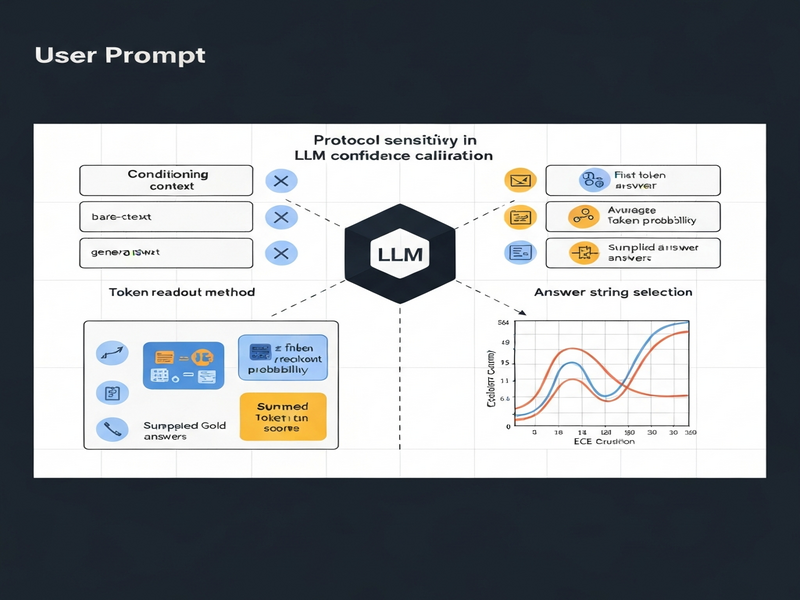
The authors introduce a protocol‑centric framework for measuring LLM confidence calibration. Rather than presenting a new algorithm, they provide a systematic way to decompose the comparison between token‑probability scores and verbalized confidence into three orthogonal axes:
- Scored answer selection: which textual answer (generated, supplied gold, or alternative plausible wrong answer) is used for extracting token probabilities.
- Token‑readout strategy: whether the probability is taken from the first token, the product of all answer tokens, or a marginalization over multiple tokenizations.
- Conditioning context: the exact prompt and surrounding dialogue history under which the model produces the answer and confidence statement.
By holding the verbalized‑confidence elicitation constant (single prompt template, fixed probability scale, and uniform output format) and varying the three axes, the study isolates how each factor influences the measured calibration gap. The framework also includes a concise reporting checklist that forces researchers to disclose every protocol decision, thereby improving transparency and reproducibility.
How It Works in Practice
The practical workflow can be visualized as a three‑stage pipeline:
- Elicitation Stage: The model receives a fixed “confidence‑elicitation” prompt (e.g., “Answer the question and then state your confidence on a 0‑100 scale”). This stage produces two outputs: the answer string and the verbalized confidence.
- Scoring Stage: Depending on the experimental condition, the researcher selects either the generated answer, a supplied gold answer, or a deliberately misleading but plausible answer. The selected string is then tokenized.
- Readout Stage: The token‑probability is extracted using one of three strategies:
- Probability of the first token only.
- Product of probabilities across all tokens (assuming independence).
- Marginalized probability that accounts for alternative tokenizations (e.g., sub‑word splits).
Finally, the token‑probability and the verbalized confidence are fed into a calibration metric—most commonly Expected Calibration Error (ECE). By swapping the scored answer, readout strategy, or conditioning context, the same underlying model can exhibit dramatically different ECE gaps.
What sets this approach apart is its explicit separation of “measurement protocol” from “model behavior.” The authors argue that confidence signals are not intrinsic properties of the model but are emergent from the interaction between model, prompt, and evaluation pipeline.
Evaluation & Results
The authors applied their framework to four widely used QA benchmarks (e.g., TriviaQA, Natural Questions) across three families of open‑source 7‑8B base and instruction‑tuned models, with larger Qwen2.5 variants serving as robustness checks. The key findings are:
- Conditioning context matters most: Switching from a “bare‑context” (only the question) to a “generated‑answer” context (question plus model‑generated answer) flipped the sign of the ECE gap in several settings. In some cases, instruction‑tuned models that previously appeared better calibrated under verbalized confidence became indistinguishable from base models.
- Token readout influences magnitude but not direction: Using the first‑token probability versus the full‑answer product changed the absolute ECE values by up to 15 %, yet the overall trend (whether verbalized confidence was better or worse) remained stable.
- ECE estimator choice is robust: Replacing the standard binning‑based ECE with a kernel‑density version produced negligible differences, confirming that the observed sensitivity stems from protocol choices rather than metric quirks.
- Supplied‑answer analysis reveals plausibility bias: When the researchers forced the model to evaluate a gold answer versus a surface‑plausible wrong answer, verbalized confidence scores were nearly identical. This suggests that the model’s confidence reflects answer plausibility and provenance, not pure correctness.
Collectively, these results demonstrate that the previously reported “large calibration gain” for verbalized confidence is an artifact of a particular experimental protocol. When the protocol is varied, the advantage can disappear or even reverse.
Why This Matters for AI Systems and Agents
For practitioners building AI‑driven products—whether chatbots, autonomous agents, or decision‑support pipelines—confidence estimates are the linchpin of safe operation. The paper’s insights translate into concrete design guidelines:
- Explicit protocol documentation: Every confidence‑related API should expose the exact prompt template, answer selection rule, and token‑readout method used. This enables downstream services to interpret the confidence correctly.
- Context‑aware calibration: Agents that switch between “answer‑first” and “answer‑plus‑confidence” interaction modes must recalibrate their confidence models for each mode, rather than assuming a single universal calibration curve.
- Robust evaluation pipelines: When benchmarking new LLMs, teams should run a matrix of protocol variations (as the authors did) to surface hidden sensitivities before shipping.
- Risk mitigation: Knowing that verbalized confidence can be swayed by answer plausibility, developers should combine it with external verification (e.g., retrieval‑augmented checks) rather than relying on it as a sole trust signal.
These practices are directly applicable to UBOS platform overview, where confidence scores drive workflow branching, and to the Workflow automation studio, which orchestrates multiple LLM calls based on calibrated uncertainty.
What Comes Next
While the study clarifies many ambiguities, it also opens several research avenues:
- Standardized calibration benchmarks: Community‑wide datasets that prescribe a full protocol (prompt, answer selection, readout) could become the “ImageNet” of confidence calibration.
- Dynamic protocol adaptation: Future agents might learn to select the most reliable confidence extraction method on the fly, based on context or downstream task requirements.
- Multi‑modal confidence: Extending the framework to vision‑language or audio‑language models will test whether protocol sensitivity persists across modalities.
- Human‑in‑the‑loop studies: Empirical work measuring how end‑users interpret verbalized versus token‑based confidence can guide UI design.
From an engineering standpoint, integrating these ideas into existing products is straightforward. For example, the OpenAI ChatGPT integration can expose both the raw token probability and the verbalized confidence, letting developers experiment with different conditioning contexts without redeploying models. Similarly, the Telegram integration on UBOS can present confidence‑aware responses that adapt their tone based on the selected protocol.
Finally, the authors provide a concise reporting checklist that any calibration experiment should follow:
- Specify the exact prompt template and any system messages.
- State which answer string is scored (generated, supplied gold, or alternative).
- Describe the token‑readout method (first token, full answer product, marginalization).
- Identify the conditioning context (bare question, answer‑included, multi‑turn dialogue).
- Report the calibration metric(s) and estimator details.
- Provide raw probability distributions when possible for reproducibility.
Adhering to this checklist will make future research more comparable and help product teams avoid hidden pitfalls when deploying confidence‑aware LLMs.
Conclusion
The paper “Asking Is Not Enough” demonstrates that confidence calibration is not a property of the model alone but a joint outcome of model, prompt, and measurement protocol. By exposing the sensitivity of calibration metrics to seemingly innocuous design choices, the authors compel the community to treat confidence signals as protocol‑dependent behavioral measurements. For AI practitioners, this means rethinking how confidence is extracted, reported, and consumed in real‑world systems. The provided framework, checklist, and empirical findings lay a solid foundation for more transparent, reliable, and ultimately safer LLM deployments.
References & Further Reading
- Kim, H., & Kang, P. (2026). Asking Is Not Enough: Protocol Sensitivity in LLM Confidence Calibration. arXiv preprint.
- Guo, C., et al. (2017). On Calibration of Modern Neural Networks. Proceedings of ICML.
- Vaswani, A., et al. (2017). Attention Is All You Need. NeurIPS.
- UBOS documentation on confidence‑aware workflows: About UBOS.