
- Updated: June 10, 2026
- 6 min read
DeepSciVerify: Verifying Scientific Claim–Citation Alignment via LLM-Driven Evidence Escalation
Direct Answer
DeepSciVerify is a two‑stage verification pipeline that checks whether a scientific claim is properly supported by its cited literature. By first reasoning over abstracts and only escalating to full‑text passages when uncertainty remains, it delivers higher accuracy while cutting down costly document retrieval.
Background: Why This Problem Is Hard
Large language models (LLMs) have become prolific generators of scientific text, from literature reviews to automated research assistants. However, a persistent failure mode is the misalignment between a claim and the evidence it cites. When a model fabricates or misinterprets a citation, downstream users—researchers, clinicians, policy makers—risk propagating false conclusions.
Existing verification pipelines typically adopt one of two extremes:
- Abstract‑only checks: Fast but shallow; they miss nuances that only appear in methods or results sections.
- Full‑text retrieval for every claim: Comprehensive but computationally expensive, often requiring large storage, network bandwidth, and latency that break real‑time workflows.
Both approaches struggle with the trade‑off between speed and fidelity. Moreover, LLMs exhibit heterogeneous behavior under uncertainty—some are overly cautious, others overly decisive—making it difficult to set a single confidence threshold that works across all claims.
What the Researchers Propose
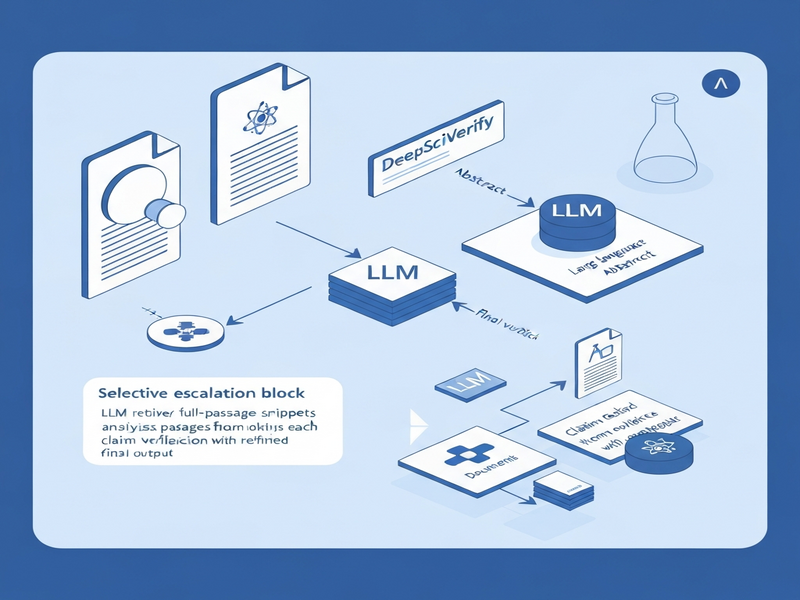
DeepSciVerify introduces a selective evidence escalation framework that leverages the complementary strengths of different LLMs. The core idea is simple yet powerful: let a conservative model perform an initial abstract‑level verification, and only hand off ambiguous cases to a more decisive model that can retrieve and analyze full‑text passages.
The framework consists of three logical agents:
- Abstract Reasoner: Uses a lightweight LLM to assess claim‑citation alignment based solely on the paper’s abstract.
- Escalation Controller: Interprets the confidence score from the Abstract Reasoner and decides whether to invoke the next stage.
- Passage Verifier: A second LLM, paired with a targeted retrieval engine, fetches relevant full‑text snippets and performs a deeper consistency check.
This division of labor creates a pipeline that is both efficient (most claims are settled early) and robust (hard cases receive full scrutiny).
How It Works in Practice
The operational flow can be broken down into four sequential steps:
1. Claim Extraction
The system receives a claim‑citation pair, typically extracted from a generated report or a manuscript draft. The claim is normalized (e.g., removing LaTeX markup) to ensure consistent processing.
2. Abstract‑Level Reasoning
The Abstract Reasoner queries the abstract of the cited paper via a metadata service (e.g., CrossRef or Semantic Scholar). It then prompts the LLM with a structured template:
“Given the abstract below, does the following claim accurately reflect the findings? Provide a confidence score between 0 and 1.”
The model returns a binary decision (support / refute) plus a confidence value.
3. Escalation Decision
The Escalation Controller compares the confidence against a dynamic threshold. If the score exceeds the threshold, the decision is final. If not, the claim is flagged for deeper analysis.
4. Passage‑Level Verification
For escalated claims, the Passage Verifier triggers a full‑text retrieval engine (e.g., a vector‑search over PDF passages). It selects the top‑k passages most semantically related to the claim, then feeds them back to a second LLM with a richer prompt that includes the claim, the retrieved passages, and a request for a justification.
The final output combines the abstract decision (if confident) or the passage‑level verdict, along with a human‑readable rationale.
The diagram below visualizes the end‑to‑end workflow:
Evaluation & Results
DeepSciVerify was benchmarked on SCitance, a curated dataset of scientific claim‑citation pairs that includes both correct and deliberately mismatched citations. The evaluation focused on two axes: verification accuracy (Micro‑F1) and retrieval efficiency (percentage of claims resolved without full‑text access).
Key Findings
- Accuracy boost: DeepSciVerify achieved a Micro‑F1 of 86.7, surpassing the best abstract‑only baseline by 4.5 points.
- Selective escalation efficiency: Approximately 67 % of claims were settled after the abstract stage, eliminating the need for costly full‑text retrieval in two‑thirds of cases.
- Robustness to uncertainty: The dual‑model design reduced false positives that typically arise when a single LLM is forced to make a decision under low confidence.
These results demonstrate that a principled escalation strategy can simultaneously improve verification quality and lower computational overhead—a win‑win for both research labs and production AI services.
Why This Matters for AI Systems and Agents
For AI‑driven research assistants, literature review bots, and autonomous scientific agents, claim‑citation fidelity is a non‑negotiable requirement. DeepSciVerify offers a plug‑and‑play verification layer that can be integrated into any pipeline that generates or consumes scientific statements.
Practical implications include:
- Reduced hallucination risk: By automatically flagging unsupported claims, downstream agents can avoid propagating errors.
- Cost‑effective scaling: Since most claims are resolved at the abstract level, cloud‑based services can handle higher query volumes without proportionally increasing storage or compute budgets.
- Improved user trust: Providing a concise rationale for each verification decision helps end‑users (researchers, clinicians) understand and trust the AI’s output.
Organizations building AI‑enhanced knowledge bases can embed DeepSciVerify into their ingestion pipelines, ensuring that every new entry meets a baseline of evidential rigor. For example, the Enterprise AI platform by UBOS could incorporate this verification step to certify the scientific integrity of its data lake.
What Comes Next
While DeepSciVerify marks a significant step forward, several avenues remain open for exploration:
- Multi‑modal evidence: Extending the passage verifier to handle tables, figures, and supplementary material could capture nuances that text alone misses.
- Adaptive thresholds: Learning a per‑domain or per‑claim confidence policy could further reduce unnecessary escalations.
- Human‑in‑the‑loop workflows: Integrating a reviewer interface where experts can correct or confirm the system’s verdict would create a feedback loop for continual model improvement.
- Cross‑domain generalization: Testing the pipeline on biomedical, engineering, and social‑science corpora will reveal how well the architecture transfers beyond the initial benchmark.
Developers interested in rapid prototyping can start by leveraging the Workflow automation studio to stitch together abstract retrieval, LLM prompting, and passage search components without writing extensive glue code.
Conclusion
DeepSciVerify demonstrates that selective evidence escalation—pairing abstract‑level reasoning with targeted full‑text analysis—can dramatically improve scientific claim verification. By balancing speed, cost, and accuracy, the framework equips AI agents with a reliable guardrail against citation hallucinations, paving the way for more trustworthy AI‑augmented research workflows.
For a deeper dive into the methodology and experimental setup, consult the original DeepSciVerify paper.