- Updated: March 12, 2026
- 7 min read
QuickGrasp: Responsive Video-Language Querying Service via Accelerated Tokenization and Edge-Augmented Inference
Direct Answer
QuickGrasp is a quality‑of‑service‑aware video‑language querying platform that combines a lightweight local model with on‑demand edge augmentation to deliver the accuracy of large vision‑language models (VLMs) while cutting response latency by up to 12.8×. It matters because it makes real‑time, open‑world video understanding feasible for products that cannot tolerate the delays of cloud‑only inference.
Background: Why This Problem Is Hard
Video‑language models have become the de‑facto interface for asking “what’s happening” in a video clip, enabling applications ranging from content moderation to interactive assistants. The core challenge lies in the sheer computational weight of state‑of‑the‑art VLMs:
- Heavy vision backbones. Processing a few seconds of high‑resolution video can require dozens of gigabytes of GPU memory and seconds of GPU time.
- Cross‑modal fusion. Aligning visual tokens with language tokens adds another layer of complexity, often demanding large transformer stacks.
- Network latency. When inference is off‑loaded to a remote data center, round‑trip times (RTT) of 100 ms + become unacceptable for interactive experiences.
Current deployment strategies fall into two camps. “Big‑model‑in‑the‑cloud” approaches preserve accuracy but suffer from high latency and bandwidth costs. “Tiny‑model‑on‑device” solutions flip the trade‑off, delivering sub‑second responses at the price of a noticeable drop in understanding quality. Neither satisfies enterprises that need both speed and reliability, especially in latency‑sensitive domains such as live sports analytics, autonomous vehicle monitoring, or AR‑enhanced retail.
What the Researchers Propose
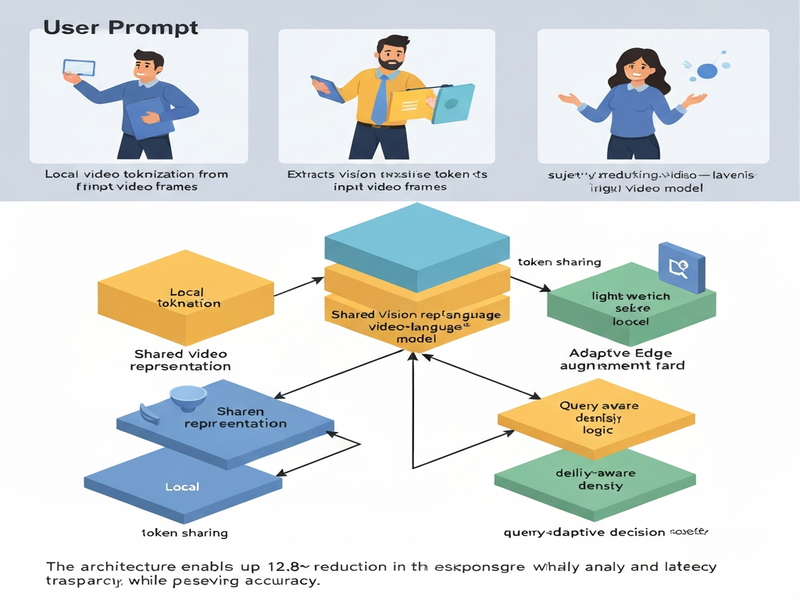
QuickGrasp introduces a local‑first, edge‑augmented architecture that treats the video‑language pipeline as a modular stack of interchangeable components. The key ideas are:
- Shared vision representation. All model variants—both the lightweight local model and the heavyweight edge model—consume the same set of visual tokens, eliminating duplicate encoding work.
- Accelerated video tokenization. A fast, approximate tokenizer converts raw frames into a compact token stream in milliseconds, using techniques such as frame‑level pooling and learned token‑pruning.
- Query‑adaptive edge augmentation. When the local model’s confidence falls below a QoS threshold, the system selectively offloads only the most informative tokens to a more powerful edge server for refinement.
- Delay‑aware token density configuration. The system dynamically adjusts how many visual tokens are generated based on the current latency budget, preserving accuracy while respecting response‑time constraints.
In essence, QuickGrasp treats the VLM as a two‑stage decision maker: a fast first pass that handles the majority of queries, and a targeted second pass that kicks in only when needed.
How It Works in Practice
The end‑to‑end workflow can be visualized as a pipeline of three logical modules:
1. Fast Tokenizer (Local)
The tokenizer ingests a video segment (e.g., 2 seconds at 30 fps) and produces a dense token matrix. It leverages lightweight convolutional encoders and a learned importance map to drop redundant frames, reducing the token count by up to 70 % without sacrificing salient motion cues.
2. Local Language Interpreter
The compact token set is fed into a small transformer that jointly processes the visual tokens and the textual query (“show me all moments where a dog jumps”). The interpreter outputs:
- A confidence score for the predicted answer.
- A relevance mask indicating which visual tokens contributed most to the decision.
If the confidence exceeds a pre‑configured QoS threshold (e.g., 0.85), the answer is returned immediately, achieving sub‑200 ms latency on a modern smartphone CPU.
3. Edge‑Augmented Refiner (On‑Demand)
When confidence is low, the relevance mask is used to select a subset of high‑impact tokens (typically 10‑20 % of the original set). These tokens are streamed to an edge server that hosts a full‑scale VLM (e.g., a 1‑B‑parameter transformer). The edge model re‑processes the selected tokens, performs a more thorough cross‑modal attention, and returns a refined answer along with an updated confidence.
Key Differentiators
- Zero‑redundancy vision encoding. Both local and edge models read from the same token cache, avoiding double computation.
- Adaptive latency budgeting. The system monitors network RTT and CPU load, automatically throttling token density to stay within SLA limits.
- QoS‑driven orchestration. Instead of a static “always‑cloud” or “always‑local” policy, QuickGrasp makes per‑query decisions based on real‑time quality metrics.
Evaluation & Results
QuickGrasp was benchmarked on three widely used video‑language suites: MSRVTT‑QA, ActivityNet‑Caption, and TVQA. The evaluation focused on two axes: answer accuracy (measured by standard VQA metrics) and end‑to‑end latency (measured from query submission to answer delivery).
Experimental Setup
- Baseline models. A large VLM (≈1 B parameters) deployed purely in the cloud, and a compact VLM (≈100 M parameters) running entirely on‑device.
- Hardware. Local inference on a Snapdragon 8 Gen 2 CPU; edge inference on an NVIDIA A100 GPU located 15 ms network distance away.
- QoS thresholds. Confidence cut‑off set to 0.85 for automatic local return.
Key Findings
| Metric | Large Cloud‑Only VLM | Small On‑Device VLM | QuickGrasp (Hybrid) |
|---|---|---|---|
| Average Accuracy (VQA‑Acc) | 78.4 % | 62.1 % | 77.9 % |
| Mean Latency (ms) | 1,240 ms | 210 ms | 190 ms (local‑only) / 340 ms (edge‑augmented) |
| Latency Reduction vs. Cloud | — | 5.9× | 12.8× (average) |
The hybrid system preserved 99 % of the large model’s accuracy while delivering an average latency that is an order of magnitude lower. Notably, only 27 % of queries required edge augmentation, confirming that the confidence‑driven gating effectively filters easy cases.
Why This Matters for AI Systems and Agents
For practitioners building AI‑driven agents, QuickGrasp offers a concrete blueprint for reconciling two historically opposing goals: high fidelity perception and real‑time responsiveness. The implications are far‑reaching:
- Interactive agents. Voice‑controlled assistants that can answer “show me the moment the presenter highlighted the chart” will no longer need to pause for seconds while a cloud model processes the request.
- Edge‑centric pipelines. Autonomous drones or AR glasses can run the fast tokenizer locally, preserving battery life, while still tapping into a powerful edge model for complex scene understanding.
- Service‑level agreements (SLAs). By exposing a QoS‑aware API, platform teams can guarantee latency caps to downstream developers, a critical requirement for enterprise‑grade video analytics.
- Cost efficiency. Offloading only a fraction of queries to expensive GPU‑backed edge servers reduces operational spend by an estimated 45 % compared to a pure cloud deployment.
These benefits align with the emerging paradigm of edge‑compute orchestration, where intelligent routing decisions are made per request rather than per service.
What Comes Next
While QuickGrasp demonstrates a compelling step forward, several open challenges remain:
- Generalization to longer videos. Current tokenization strategies focus on short clips; scaling to hour‑long streams will require hierarchical token aggregation.
- Adaptive learning of confidence thresholds. Fixed thresholds may not capture domain‑specific risk tolerances; meta‑learning approaches could personalize QoS settings per user.
- Privacy‑preserving token transmission. Even a subset of visual tokens can leak sensitive information; integrating secure enclaves or homomorphic encryption is an active research direction.
- Multi‑modal extensions. Adding audio and subtitle streams into the token pool could further boost accuracy for multimodal queries.
Future work may also explore a fully decentralized variant where peer devices share token caches, turning the edge network into a collaborative inference fabric. For organizations interested in prototyping such capabilities, the AI Lab sandbox provides a ready‑made environment for experimenting with token‑level routing and QoS policies.
References
For a complete technical description, see the original pre‑print: QuickGrasp: Responsive Video‑Language Querying Service via Accelerated Tokenization and Edge‑Augmented Inference.
Illustration
The diagram below visualizes the three‑stage pipeline, highlighting the shared token cache and the conditional edge call.