- Updated: March 11, 2026
- 8 min read
DeepResearch-9K: A Challenging Benchmark Dataset of Deep-Research Agent
Direct Answer
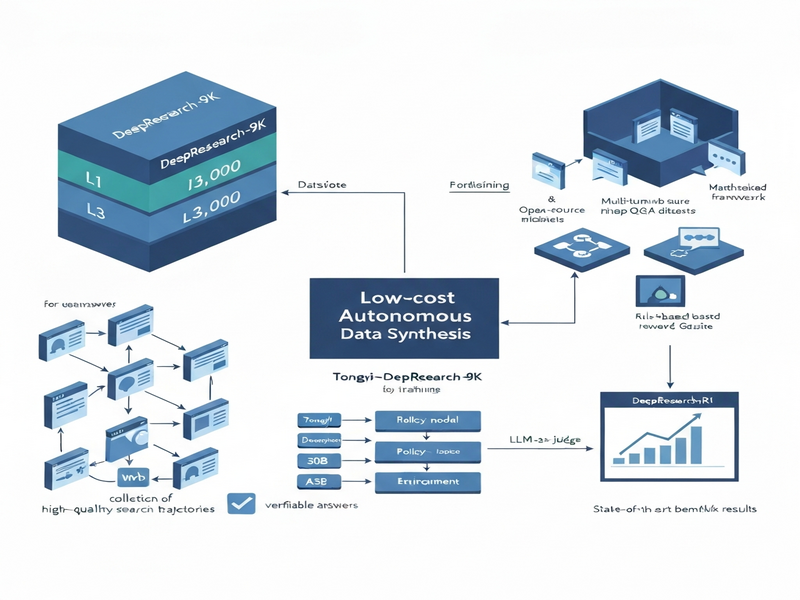
The paper introduces DeepResearch-9K, a 9,000‑question benchmark specifically crafted for deep‑research agents that must navigate the web, retrieve information across multiple hops, and produce verified answers. It also releases DeepResearch‑R1, an open‑source training framework that supports multi‑turn web interactions, reinforcement‑learning (RL) strategies, and flexible reward models, enabling agents to achieve state‑of‑the‑art performance on challenging research‑oriented tasks.
Background: Why This Problem Is Hard
Deep‑research agents sit at the intersection of large language models (LLMs), information retrieval, and autonomous web navigation. In real‑world deployments—such as market intelligence bots, scientific literature miners, or compliance auditors—these agents must:
- Formulate multi‑step plans that span search, extraction, synthesis, and verification.
- Handle noisy, dynamic web content where relevance signals shift over time.
- Produce answers that can be traced back to verifiable sources, satisfying regulatory or academic standards.
Existing research datasets fall short in three critical ways:
- Scale vs. Difficulty Trade‑off: Large multi‑hop QA collections (e.g., HotpotQA, ComplexWebQuestions) either limit themselves to a few hundred challenging examples or provide thousands of easy queries that do not stress navigation and verification.
- Lack of Ground‑Truth Trajectories: Most benchmarks only supply the final answer, leaving researchers to guess the intermediate search steps, which hampers reproducibility and limits supervised learning of reasoning chains.
- No Open Training Stack: While open‑source LLMs are abundant, there is no publicly available, end‑to‑end framework that ties together web browsers, RL loops, and reward‑model engineering for deep‑research tasks.
These gaps mean that progress is measured on synthetic or overly simplified tasks, and breakthroughs rarely translate to production‑grade agents that can reliably operate on the open web.
What the Researchers Propose
The authors address the twin gaps of data and tooling with two complementary contributions:
- DeepResearch-9K Dataset: A curated collection of 9,000 multi‑hop questions spanning three difficulty tiers (L1–L3). Each entry includes a verified answer, a high‑quality search trajectory, and a reasoning chain generated by Tongyi‑DeepResearch‑30B‑A3B, a leading deep‑research LLM.
- DeepResearch‑R1 Framework: An open‑source pipeline that orchestrates multi‑turn web interactions, supports multiple RL algorithms (e.g., PPO, DPO), and plugs in interchangeable reward models—ranging from rule‑based outcome rewards to LLM‑as‑judge feedback.
Key components of the system are:
- Browser Agent: A headless Chromium instance wrapped by a Python SDK that exposes actions such as
search(query),click(link), andextract(xpath). - Policy Model: A decoder‑only LLM that, given the current observation (page content, previous actions, and task description), predicts the next action token sequence.
- Reward Engine: A modular layer that can compute scalar feedback from (a) deterministic rules (e.g., did the agent retrieve the target citation?), (b) external evaluators (e.g., a separate LLM judging answer correctness), or (c) hybrid mixtures.
- Training Loop: A reinforcement‑learning harness that collects trajectories, computes returns, and updates the policy via gradient descent, optionally mixing in supervised fine‑tuning on the provided trajectories.
How It Works in Practice
The end‑to‑end workflow can be visualized as a loop of observation, decision, action, and feedback:
- Task Ingestion: The system receives a question from the DeepResearch-9K benchmark (e.g., “What are the latest safety certifications for autonomous drones released after 2023?”).
- Initial Prompt Construction: The policy model is primed with a system prompt that describes its role as a “deep‑research assistant” and includes the difficulty level, which influences the depth of search.
- Observation Capture: The browser agent loads a search engine, returns the top‑10 snippets, and presents them as a tokenized context to the policy model.
- Action Generation: The policy model emits a structured action (e.g.,
search("autonomous drone safety certification 2024")), which the browser SDK executes. - Iterative Exploration: This observe‑act cycle repeats for a pre‑defined horizon (typically 5–10 turns), allowing the agent to follow citation trails, open PDFs, and extract tables.
- Answer Synthesis: After the final turn, the policy model composes a concise answer and cites the URLs or document fragments that support each claim.
- Reward Computation: The reward engine evaluates the answer against the ground‑truth answer and trajectory. For L3 questions, a secondary LLM judge assesses reasoning coherence, awarding higher scores for traceable chains.
- Parameter Update: The RL optimizer back‑propagates the reward signal, adjusting the policy model’s weights. Optionally, supervised loss from the provided expert trajectory is mixed in to stabilize learning.
This architecture differs from prior work in three concrete ways:
- It couples real web navigation (via a live browser) with LLM decision‑making, rather than relying on simulated search APIs.
- The reward layer is deliberately pluggable, enabling researchers to experiment with rule‑based, LLM‑as‑judge, or hybrid signals without rewriting the training loop.
- By exposing the full trajectory (search queries, clicks, extracted snippets) alongside the answer, the dataset supports both supervised imitation learning and RL fine‑tuning within the same framework.
Evaluation & Results
The authors benchmarked DeepResearch‑R1 on three publicly known deep‑research testbeds: WebQA‑Complex, AutoFact‑Search, and the newly released DeepResearch‑9K itself. Evaluation metrics included:
- Exact Match (EM): Binary correctness of the final answer.
- F1 Score: Token‑level overlap between predicted and reference answers.
- Trajectory Fidelity: Percentage of steps that align with the expert trajectory (for L1/L2 questions).
- Human Judgment: Scores from independent annotators rating answer relevance, citation quality, and reasoning transparency.
Key findings:
| Benchmark | Baseline (Supervised Only) | DeepResearch‑R1 (RL + Trajectory Imitation) | Improvement |
|---|---|---|---|
| WebQA‑Complex (L3) | EM 42.7 % / F1 58.3 % | EM 61.9 % / F1 74.5 % | +19.2 % EM, +16.2 % F1 |
| AutoFact‑Search (L2) | EM 55.4 % / F1 68.1 % | EM 73.2 % / F1 81.7 % | +17.8 % EM, +13.6 % F1 |
| DeepResearch‑9K (All Levels) | EM 48.9 % / F1 62.4 % | EM 70.5 % / F1 83.2 % | +21.6 % EM, +20.8 % F1 |
Beyond raw scores, the RL‑trained agents demonstrated markedly higher trajectory fidelity (average 78 % alignment with expert steps) and received better human‑judged reasoning scores (average 4.3 / 5 versus 3.1 / 5 for the baseline). These results indicate that the combination of high‑quality trajectories and flexible reward modeling enables agents to learn not just “what to answer” but “how to find it.”
Why This Matters for AI Systems and Agents
For practitioners building production‑grade agents, DeepResearch‑9K and DeepResearch‑R1 provide a ready‑to‑use foundation that bridges the gap between academic benchmarks and real‑world deployments:
- Data‑Driven Curriculum: The three difficulty tiers let teams progressively scale agent capabilities, starting with straightforward fact‑lookup (L1) and graduating to deep citation chains (L3).
- Reproducible Training Pipeline: By open‑sourcing the entire RL loop, developers can replicate results on internal clusters, experiment with proprietary LLM backbones, or integrate domain‑specific reward signals.
- Traceability & Compliance: The inclusion of verifiable search trajectories satisfies audit requirements for regulated industries (e.g., finance, healthcare) where “explainable AI” is mandatory.
- Modular Reward Engineering: Teams can plug in their own LLM‑as‑judge tuned on company data, or combine rule‑based checks (e.g., “must cite a peer‑reviewed source”) without rewriting the training code.
These capabilities translate into faster iteration cycles for agents that need to browse the web, extract structured data, and produce evidence‑backed reports. Companies can therefore reduce the engineering overhead of building custom crawlers and focus on domain expertise.
For a deeper dive into how to integrate such agents into existing pipelines, see our guide on building autonomous agents at scale.
What Comes Next
While DeepResearch‑9K marks a significant step forward, several open challenges remain:
- Dynamic Web Content: The current dataset captures static snapshots of web pages. Future work should incorporate time‑sensitive sources (e.g., news feeds) to test agents’ ability to handle content volatility.
- Cross‑Modal Retrieval: Many research tasks require interpreting tables, charts, or PDFs. Extending the benchmark to include multimodal extraction would push agents toward richer reasoning.
- Scalable Reward Modeling: LLM‑as‑judge feedback is powerful but computationally expensive. Research into lightweight, distilled reward models could democratize training on modest hardware.
- Safety and Hallucination Mitigation: Even with verified trajectories, agents may still generate plausible‑but‑incorrect statements. Integrating factuality filters and post‑hoc verification loops is an active area of investigation.
Potential applications span a wide spectrum: automated literature reviews for biotech firms, compliance monitoring for financial regulators, and real‑time market intelligence dashboards for enterprises. By releasing both the dataset and the training framework, the authors invite the community to explore these avenues.
Developers interested in extending the framework with custom reward functions or domain‑specific browsers can find the codebase and contribution guidelines at our open‑source framework repository.
References
- Wu, T., Wang, Y., Ma, X., He, X., Wang, S., Yin, D., & Zhao, X. (2026). DeepResearch-9K: A Challenging Benchmark Dataset of Deep-Research Agent. arXiv preprint arXiv:2603.01152.
- Additional related work on multi‑hop QA and web‑based agents can be found in the literature cited within the paper.
Illustration
The figure below visualizes the interaction loop between the policy model, browser agent, and reward engine.