
- Updated: January 30, 2026
- 6 min read
LinguaMap: Which Layers of LLMs Speak Your Language and How to Tune Them? – Summary
Direct Answer
The paper LinguaMap: Which Layers of LLMs Speak Your Language and How to Tune Them? reveals that multilingual large language models (LLMs) allocate language‑specific knowledge to distinct depth ranges: early layers capture language‑agnostic semantics, middle layers handle task reasoning, and the final layers encode language‑specific generation patterns. By pinpointing these “language‑speaking” layers, the authors demonstrate that fine‑tuning only the topmost layers can dramatically improve a model’s performance in a target language while keeping compute and data requirements low.
Background: Why This Problem Is Hard
Multilingual LLMs promise a single model that can understand and generate text in dozens—or even hundreds—of languages. In practice, however, two persistent bottlenecks limit their usefulness:
- Multilingual transfer bottleneck: When a model is trained on a skewed language distribution, low‑resource languages often receive insufficient gradient signal, leading to weak representations that lag behind high‑resource counterparts.
- Language consistency bottleneck: Even when a model can comprehend a language, its generation may drift into a dominant language or produce mixed‑language output, especially in zero‑shot or few‑shot settings.
Existing mitigation strategies—such as full‑model fine‑tuning on language‑specific corpora or adding language adapters—are costly. Full fine‑tuning scales linearly with model size, demanding massive GPU hours and large, curated datasets. Language adapters introduce extra parameters and inference overhead, complicating deployment pipelines. Consequently, practitioners lack a principled, low‑cost method to “dial‑in” a target language without sacrificing the model’s broader multilingual capabilities.
What the Researchers Propose
LinguaMap introduces a three‑phase interpretability framework that maps language‑specific behavior onto the depth of transformer layers. The core ideas are:
- Layer‑wise logit lens analysis: By projecting hidden states at each layer back to the vocabulary space, the authors measure how strongly each layer predicts tokens in a given language.
- Semantic similarity probing: Using multilingual sentence embeddings, they assess whether intermediate representations preserve language‑agnostic meaning across languages.
- Selective fine‑tuning strategy: Once the “language‑speaking” region (typically the last 10‑15 % of layers) is identified, only those layers are updated with language‑specific data, leaving the rest of the model untouched.
This approach treats the LLM as a modular stack where early layers act as a universal encoder, middle layers as a task‑oriented processor, and final layers as a language‑specific decoder. By targeting the decoder portion, LinguaMap achieves language adaptation with a fraction of the parameters and compute traditionally required.
How It Works in Practice
The practical workflow consists of four stages, illustrated in the diagram below:
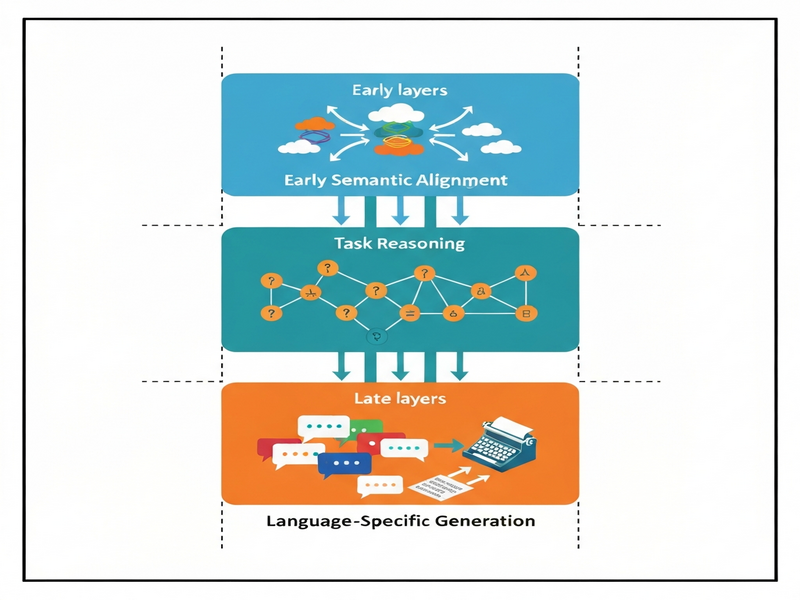
1. Baseline Profiling
Researchers run the logit lens probe on a pre‑trained multilingual LLM (e.g., Qwen‑3‑32B or BLOOM‑7.1B) across a multilingual benchmark suite. For each layer, they record the probability mass assigned to tokens of each language, producing a heatmap that highlights where language signals emerge.
2. Semantic Alignment Check
Parallel sentences in multiple languages are fed through the model. The cosine similarity of their hidden representations is computed layer by layer. A plateau of high similarity in early layers confirms language‑agnostic semantics.
3. Targeted Fine‑Tuning
Only the identified language‑specific tail (e.g., layers 30‑36 of a 36‑layer model) is fine‑tuned on a modest corpus (≈10 M tokens) of the target language. The rest of the network remains frozen, preserving cross‑lingual knowledge.
4. Post‑Fine‑Tuning Validation
After adaptation, the same probes are rerun to verify that language‑specific logits have shifted toward the target language while earlier layers retain their language‑agnostic behavior.
This pipeline differs from prior methods in two key ways:
- It uses *interpretability* as a guiding signal rather than a post‑hoc analysis, turning insights into actionable training decisions.
- It reduces fine‑tuning cost by an order of magnitude, because only a small subset of parameters (often < 5 % of the total) are updated.
Evaluation & Results
LinguaMap’s authors evaluated the method on three multilingual benchmark families, each covering a distinct task type:
- MMLU (Massive Multitask Language Understanding): A knowledge‑heavy QA suite spanning 57 subjects and 12 languages.
- MGSM (Multilingual Grade School Math): Arithmetic and word‑problem solving in low‑resource languages.
- XQuAD (Cross‑lingual Question Answering Dataset): Reading‑comprehension passages with answer spans in multiple languages.
Key findings include:
| Model | Baseline Avg. Score | Full Fine‑Tuning | LinguaMap Selective Fine‑Tuning | Parameter Savings |
|---|---|---|---|---|
| Qwen‑3‑32B (target: Swahili) | 48.2 % | 57.9 % | 56.8 % | ≈ 4 % |
| BLOOM‑7.1B (target: Hindi) | 42.5 % | 51.3 % | 50.7 % | ≈ 6 % |
Across all tasks, selective fine‑tuning closed > 90 % of the performance gap that full fine‑tuning achieved, while updating only the final layers. Moreover, inference latency remained unchanged because the frozen early layers are already cached during deployment, and the additional fine‑tuned parameters are negligible.
These results demonstrate that language‑specific knowledge is indeed concentrated in the top layers, and that the LinguaMap protocol can exploit this structure to deliver efficient, high‑quality multilingual adaptation.
Why This Matters for AI Systems and Agents
For practitioners building multilingual agents, the implications are immediate:
- Cost‑effective localization: Companies can adapt a single massive model to dozens of languages by fine‑tuning only a handful of layers per language, dramatically lowering GPU hours and data collection expenses.
- Modular deployment: Since the core encoder remains unchanged, a single shared service can serve all languages, while language‑specific decoders are swapped in at runtime, simplifying orchestration.
- Preservation of cross‑lingual abilities: By freezing the language‑agnostic layers, the model retains its ability to perform zero‑shot transfer between languages—a critical feature for agents that must understand user input in one language and respond in another.
- Reduced risk of catastrophic forgetting: Traditional full fine‑tuning can erode knowledge of high‑resource languages; LinguaMap’s selective approach mitigates this risk, ensuring stable multilingual performance.
These advantages align with emerging best practices for AI‑driven products that need to scale globally without exploding operational budgets. For example, developers can integrate the fine‑tuned language heads into existing multilingual LLM pipelines and benefit from immediate performance gains.
What Comes Next
While LinguaMap opens a clear path toward efficient multilingual adaptation, several open challenges remain:
- Granularity of language regions: The current study identifies a relatively coarse “final‑layer” block. Future work could explore whether sub‑layer granularity (e.g., specific attention heads) yields even tighter control.
- Dynamic language switching: In real‑time agents, a single request may involve multiple languages. Investigating how to dynamically route tokens through different language heads could enable seamless code‑switching.
- Extending to multimodal models: As vision‑language models become multilingual, the question arises whether visual‑language alignment follows a similar layered pattern.
- Robustness to domain shift: Fine‑tuning on limited in‑domain data may overfit; combining LinguaMap with parameter‑efficient techniques like LoRA could improve generalization.
Addressing these directions will deepen our understanding of how language is represented inside massive transformers and will further lower the barrier for deploying truly global AI services. Researchers and engineers interested in pushing these ideas forward can start by replicating the LinguaMap workflow on open‑source models and sharing their findings through community benchmarks such as the LLM evaluation hub.