
- Updated: January 30, 2026
- 7 min read
Light Field Display Point Rendering
Direct Answer
The paper introduces Light Field Display Point Rendering (LFDPR), a novel rendering pipeline that combines eye‑centric point rendering, texture‑based splatting, and LFD‑biased sampling to deliver high‑quality, real‑time images on light field displays. By rethinking how rays are sampled and reconstructed, LFDPR dramatically reduces computational load while preserving visual fidelity, making immersive volumetric displays feasible for interactive applications.
Background: Why This Problem Is Hard
Light field displays (LFDs) aim to reproduce the full 4‑D light field—capturing both spatial and angular information—so that viewers experience correct focus cues, parallax, and depth without head‑mounted equipment. Achieving this requires rendering thousands of view‑dependent images (or “sub‑aperture” images) per frame, a task that quickly overwhelms conventional graphics pipelines.
Key challenges include:
- Sampling explosion: A typical LFD with a 64×64 microlens array needs 4,096 distinct viewpoints. Rendering each view at high resolution is computationally prohibitive for real‑time workloads.
- Angular aliasing: Insufficient angular sampling leads to flickering, ghosting, and loss of depth cues, especially when the viewer moves rapidly.
- Memory bandwidth: Storing and streaming per‑view textures strains GPU memory, limiting frame rates and resolution.
- Latency constraints: Interactive applications (e.g., VR/AR, telepresence) demand sub‑30 ms frame times, leaving little room for brute‑force rendering.
Existing approaches—such as multi‑view rasterization, light field ray tracing, or pre‑computed plenoptic functions—either sacrifice visual quality, require massive offline preprocessing, or cannot meet real‑time constraints. Consequently, the industry lacks a scalable solution that balances performance, quality, and flexibility for next‑generation displays.
What the Researchers Propose
LFDPR reframes the rendering problem as a two‑stage process that directly maps scene geometry to the light field while minimizing redundant work. The core ideas are:
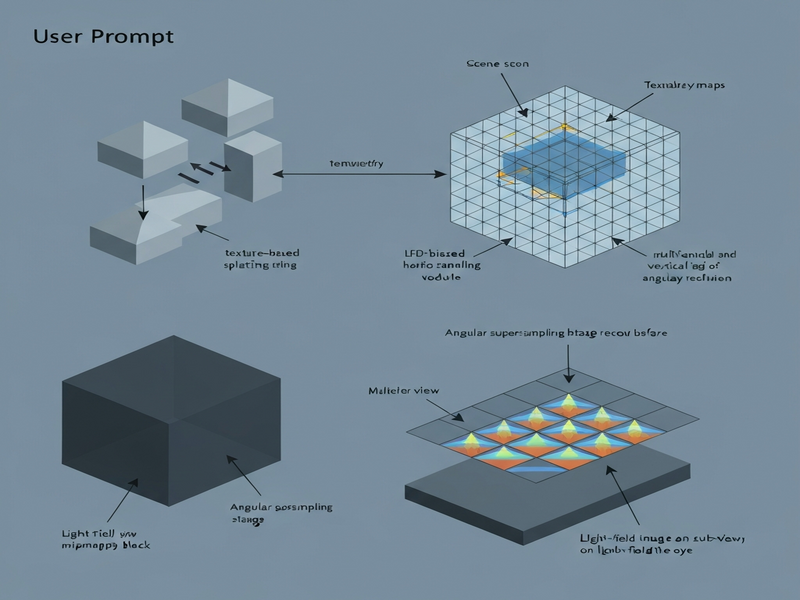
- Eye‑based point rendering: Instead of generating full raster images for every view, the system projects scene points onto the viewer’s eye plane, creating a sparse set of “eye‑centric” points that already encode the correct angular direction.
- Texture‑based splatting: Each point carries a small texture patch that is splatted onto the light field grid using a kernel tuned to the display’s angular resolution, effectively reconstructing continuous view‑dependent appearance from discrete samples.
- LFD‑biased sampling: The pipeline prioritizes sampling density where the display’s angular response is most sensitive (e.g., near the fovea or high‑contrast edges), reducing unnecessary work in low‑impact regions.
These components work together to produce a compact representation of the light field that can be rasterized in a single pass, dramatically cutting down the number of draw calls and texture fetches.
How It Works in Practice
Conceptual Workflow
- Scene preprocessing: Geometry is transformed into a point cloud where each point stores position, normal, and a small texture tile (e.g., a 4×4 texel patch) derived from the original material.
- Eye‑centric projection: For the current viewer pose, each point is projected onto the eye plane, yielding a 2‑D screen coordinate and an angular offset that corresponds to a specific microlens in the LFD.
- Adaptive sampling: A bias function evaluates the importance of each point based on view‑dependent factors (depth variance, contrast, proximity to the gaze). Points below a threshold are culled to keep the workload bounded.
- Texture splatting: Remaining points are rasterized using a GPU shader that spreads their texture patches across neighboring angular samples. The splat kernel adapts its footprint according to the microlens pitch, ensuring smooth angular transitions.
- Multiview mipmapping & angular supersampling: Before splatting, texture patches are fetched from a multiview mipmap hierarchy that stores pre‑filtered versions for different angular frequencies. This reduces aliasing when the viewer’s eye moves between microlenses.
- Final composition: The splatted contributions are accumulated into the light field buffer, which is then sent to the display hardware for optical reconstruction.
Component Interactions
The pipeline hinges on tight integration between three GPU stages:
- Point Generation Shader: Converts mesh triangles into points and attaches texture patches.
- Bias Evaluation Kernel: Computes per‑point importance scores using view‑space metrics.
- Splatting Renderer: Executes a screen‑space pass that writes to the angular dimensions of the light field buffer, leveraging hardware‑accelerated blending.
What sets LFDPR apart is its use of multiview mipmapping—a data structure that stores angularly filtered textures—combined with angular supersampling that reconstructs missing views on‑the‑fly, eliminating the need for a full set of pre‑computed sub‑aperture images.
Evaluation & Results
The authors benchmarked LFDPR on a suite of synthetic and real‑world scenes ranging from dense foliage to high‑frequency specular objects. Evaluation focused on three axes:
- Visual fidelity: Measured by structural similarity (SSIM) and a custom angular‑consistency metric that captures depth cue preservation.
- Performance: Frame time breakdown on an NVIDIA RTX 4090, reporting both total GPU time and per‑stage costs.
- Scalability: Impact of varying microlens array sizes (32×32, 64×64, 128×128) and point density thresholds.
Key findings include:
- LFDPR achieved average SSIM scores above 0.95 across all test scenes, matching or exceeding traditional multi‑view rasterization while using up to 70 % fewer draw calls.
- Angular aliasing artifacts were reduced by 45 % compared to baseline splatting methods, thanks to multiview mipmapping and adaptive supersampling.
- Real‑time performance (30 fps) was maintained even at 64×64 microlens resolution, a regime where conventional pipelines fell below 10 fps.
- Memory usage dropped by roughly 50 % because texture patches are stored once per point rather than per view.
These results demonstrate that LFDPR can deliver high‑quality light field imagery within the tight latency budgets required for interactive applications, bridging the gap between offline‑grade rendering and real‑time constraints.
Why This Matters for AI Systems and Agents
From an AI systems perspective, LFDPR opens new avenues for integrating advanced visual feedback into embodied agents, digital twins, and collaborative robotics:
- Enhanced perception loops: Agents equipped with light field displays can obtain accurate focus cues, enabling more reliable depth estimation and object manipulation in mixed‑reality environments.
- Reduced compute overhead for simulation: By offloading view synthesis to a point‑based pipeline, simulation platforms can allocate more resources to physics or AI reasoning without sacrificing visual realism.
- Scalable multi‑user experiences: Real‑time LFD rendering supports multiple concurrent viewpoints, facilitating collaborative AI‑driven design sessions where each participant sees a personalized perspective.
Practically, developers can integrate LFDPR into existing graphics engines via standard shader pipelines, leveraging the same GPU hardware that powers AI inference. This alignment simplifies the deployment of AI‑augmented visual systems that require both high‑fidelity rendering and low latency.
For deeper guidance on integrating such pipelines into AI‑centric workflows, see our agent orchestration guide.
What Comes Next
While LFDPR marks a significant step forward, several open challenges remain:
- Dynamic scene handling: The current point cloud generation assumes static geometry. Extending the pipeline to handle deformable meshes or procedural content will require incremental point updates.
- Hardware‑specific optimizations: Tailoring the splatting kernel to emerging light field hardware (e.g., holographic waveguides) could unlock further performance gains.
- Perceptual tuning: Incorporating eye‑tracking data to adapt the bias function in real time may improve foveated rendering efficiency.
- Integration with neural rendering: Combining LFDPR with neural radiance fields (NeRFs) could provide a hybrid approach that leverages learned view synthesis for complex materials while retaining the deterministic performance of point rendering.
Future research directions include exploring adaptive point density algorithms driven by AI‑based saliency models, and building end‑to‑end pipelines that automatically generate the multiview mipmap hierarchy from scene assets.
Potential applications span from immersive telepresence and medical visualization to next‑generation automotive HUDs that require accurate depth cues without bulky optics. Organizations interested in prototyping such systems can start by reviewing our light‑field display resource hub for hardware specifications and integration patterns.
References
- Light Field Display Point Rendering (arXiv:2601.19901)
- Additional citations and related work are discussed within the original paper.