MCP Docling Server
An MCP server that provides document processing capabilities using the Docling library.
Installation
You can install the package using pip:
pip install -e .
Usage
Start the server using either stdio (default) or SSE transport:
# Using stdio transport (default)
mcp-server-lls
# Using SSE transport on custom port
mcp-server-lls --transport sse --port 8000
If you’re using uv, you can run the server directly without installing:
# Using stdio transport (default)
uv run mcp-server-lls
# Using SSE transport on custom port
uv run mcp-server-lls --transport sse --port 8000
Available Tools
The server exposes the following tools:
convert_document: Convert a document from a URL or local path to markdown format
source: URL or local file path to the document (required)enable_ocr: Whether to enable OCR for scanned documents (optional, default: false)ocr_language: List of language codes for OCR, e.g. [“en”, “fr”] (optional)
convert_document_with_images: Convert a document and extract embedded images
source: URL or local file path to the document (required)enable_ocr: Whether to enable OCR for scanned documents (optional, default: false)ocr_language: List of language codes for OCR (optional)
extract_tables: Extract tables from a document as structured data
source: URL or local file path to the document (required)
convert_batch: Process multiple documents in batch mode
sources: List of URLs or file paths to documents (required)enable_ocr: Whether to enable OCR for scanned documents (optional, default: false)ocr_language: List of language codes for OCR (optional)
qna_from_document: Create a Q&A document from a URL or local path to YAML format
source: URL or local file path to the document (required)no_of_qnas: Number of expected Q&As (optional, default: 5)- Note: This tool requires IBM Watson X credentials to be set as environment variables:
WATSONX_PROJECT_ID: Your Watson X project IDWATSONX_APIKEY: Your IBM Cloud API keyWATSONX_URL: The Watson X API URL (default: https://us-south.ml.cloud.ibm.com)
get_system_info: Get information about system configuration and acceleration status
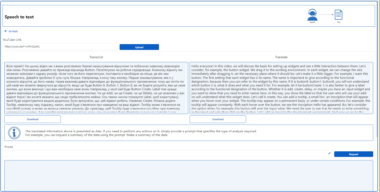
Example with Llama Stack
https://github.com/user-attachments/assets/8ad34e50-cbf7-4ec8-aedd-71c42a5de0a1
You can use this server with Llama Stack to provide document processing capabilities to your LLM applications. Make sure you have a running Llama Stack server, then configure your INFERENCE_MODEL
from llama_stack_client.lib.agents.agent import Agent
from llama_stack_client.lib.agents.event_logger import EventLogger
from llama_stack_client.types.agent_create_params import AgentConfig
from llama_stack_client.types.shared_params.url import URL
from llama_stack_client import LlamaStackClient
import os
# Set your model ID
model_id = os.environ["INFERENCE_MODEL"]
client = LlamaStackClient(
base_url=f"http://localhost:{os.environ.get('LLAMA_STACK_PORT', '8080')}"
)
# Register MCP tools
client.toolgroups.register(
toolgroup_id="mcp::docling",
provider_id="model-context-protocol",
mcp_endpoint=URL(uri="http://0.0.0.0:8000/sse"))
# Define an agent with MCP toolgroup
agent_config = AgentConfig(
model=model_id,
instructions="""You are a helpful assistant with access to tools to manipulate documents.
Always use the appropriate tool when asked to process documents.""",
toolgroups=["mcp::docling"],
tool_choice="auto",
max_tool_calls=3,
)
# Create the agent
agent = Agent(client, agent_config)
# Create a session
session_id = agent.create_session("test-session")
def _summary_and_qna(source: str):
# Define the prompt
run_turn(f"Please convert the document at {source} to markdown and summarize its content.")
run_turn(f"Please generate a Q&A document with 3 items for source at {source} and display it in YAML format.")
def _run_turn(prompt):
# Create a turn
response = agent.create_turn(
messages=[
{
"role": "user",
"content": prompt,
}
],
session_id=session_id,
)
# Log the response
for log in EventLogger().log(response):
log.print()
_summary_and_qna('https://arxiv.org/pdf/2004.07606')
Caching
The server caches processed documents in ~/.cache/mcp-docling/ to improve performance for repeated requests.
Docling Server

Project Details
- zanetworker/mcp-docling
- MIT License
- Last Updated: 4/12/2025
Recomended MCP Servers
CTX: The missing link between your codebase and your LLM. Context as Code (CaC) tool with MCP server...
An MCP server for playing Minesweeper
MCP-Server for SAP ABAP wrapping abap-adt-api
An MCP server implementation enabling LLMs to work with new APIs and frameworks
MCP Server for kicking off and getting status of your crew deployments
mcp webhook
kom 是一个用于 Kubernetes 操作的工具,SDK级的kubectl、client-go的使用封装。并且支持作为管理k8s 的 MCP server。 它提供了一系列功能来管理 Kubernetes 资源,包括创建、更新、删除和获取资源,甚至使用SQL查询k8s资源。这个项目支持多种 Kubernetes 资源类型的操作,并能够处理自定义资源定义(CRD)。 通过使用 kom,你可以轻松地进行资源的增删改查和日志获取以及操作POD内文件等动作。
MCP server for querying the Shodan API
A MCP server for the stock market data API, Alphavantage API.
Model Context Protocol Servers for Azure AI Search
Featured Templates
View More